Численное дифференцирование
Очень часто приходится сталкиваться с ситуацией, когда при численном решении той или иной задачи необходимо вычислить производную или решить дифференциальное уравнение — в численном виде, разумеется. В этих случаях используется все та же процедура dsolvef), что уже встречалась ранее при решении дифференциальных уравнений в аналитическом виде. Однако для нахождения численного решения (или производной в численном виде) при вызове процедуры следует указать опцию numeric. Во всем остальном синтаксис вызова процедуры практически такой же, как и при поиске аналитических решений, но некоторые отличия все же имеются.
Процедура может использоваться, как уже отмечалось, для вычисления производных, а также решения задач Коши и краевых задач. По умолчанию при решении задач Коши применяется метод Рунге-Кутта-Фэлберга (Runge-Kutta-Fehlbeig) порядка четыре-пять, а при решении краевых задач — экстраполяция Ричардсона (Richardson). Метод может быть изменен явным указанием значения опции method. Возможные значения опции и их описание приведены в табл. 7.4.
Таблица 7.4. Значения опции method
| Значение опции | Описание |
| bvp | Используется при решении краевых задач. Тип задачи (то ли это задача Коши, то ли краевая задача) вычислительным ядром Maple определяется автоматически Поэтому значение для опции указывается в таком формате: method=bvp[метод] В качестве iaoiaa могут указываться значения: trapdef er (метод трапеций), middef ег (метод средней точки), traprich (усовершенствованная схема для метода трапеций) или midrich (усовершенствованная схема для метода средней точки). По умолчанию используется метод traprich |
| classical | Классический метод построения численного решения. Допускается два типа определения значения: method=classical или method-classical [метод]. Здесь метод может быть таким: f oreuler (прямой метод Эйлера; используется по умолчанию), heun-f orm (усовершенствованный метод Эйлера, или правило трапеций), impoly (модифицированный метод Эйлера), rk2 (классический метод Рунге-Кутта второго порядка), гкЗ (классический метод Рунге-Кутта третьего порядка), rk4 (классический метод Рун-ге-Кута четвертого порядка), adambash (метод Адамса-Бэшфорда (Adams-Bashford), или метод предиктора) или abmoulton (метод Адамса-Бэшфорда-Молтона (Adams-Bashford-Moulton), или метод предиктора-корректора) |
| dverk78 | Метод Рунге-Кутта порядка семь-восемь |
| gear | Метод простой экстраполяции. Метод можно конкретизировать, указав method=gear[bstoer] или method=gear[polyextr]. В первом случае используется рациональная экстраполяция, во втором — полиномиальная |
| lsode | Опция активизации утилиты решения жестких дифференциальных задач. Допускается восемь встроенных методов, среди которых вызываемый по умолчанию метод Адамса с использованием функциональных итераций без вычисления функционального определителя (adamsf unc), метод Адамса с использованием итераций и вычислением полного функционального определителя (adamsf ull), метод Адамса с использованием итераций и вычислением диагонального функционального определителя (adamsdiag), метод Адамса с вычислением ленточного функционального определителя (adamsband), метод обратного дифференцирования с использованием функциональных итераций (backf unc), метод обратного дифференцирования с использованием итераций и вычислением полного функционального определителя (backf ull), метод обратного дифференцирования с использованием итераций и вычислением диагонального функционального определителя (backdiag) и метод обратного дифференцирования с использованием итераций и вычислением ленточного функционального определителя (backhand). При использовании методов adamsband и backhand необходимо также задавать параметры функциональной матрицы |
| rkf45 | Метод Рунге-Кутта-Фэлберга порядка четыре-пять |
| rosenbrock | Метод Рунге-Кутта-Розенброка (Rosenbrock) порядка три-четыре |
| taylorseries | Решение ищется в виде разложения в ряд Тейлора |
Кроме опции method, могут быть задействованы и другие опции. Они приведены в табл. 7.5.
Таблица 7.5. Некоторые опции процедуры dsolve()
| Опция | Тип значения | Описание |
| abserr | Число | Опцией устанавливается допустимая погрешность. Опция может использоваться со всеми методами, кроме classical. Кроме того, в методе rkf-45 допустимая погрешность фиксирована и определяется в основном значением переменной среды Digits |
| output | Ключевое слово или массив | Значением может быть одно из ключевых слов — procedurelist (значение по умолчанию), listprocedure или piecewise (добавлено в Maple 9) или список значений переменной, для которых следует вычислить значение выражения. При значении опции, равном procedurelist, независимая переменная является аргументом процедуры, а результат выводится в виде списка, в котором указываются через знак равенства: независимая переменная и ее значение, зависимая переменная и ее значение, производные от зависимой переменной по независимой и их значения. Если значение опции установить равным listprocedure, то результат для перечисленных выше параметров будет выводиться не через указание их значений, а через указание процедур, которые могут быть использованы для вычисления значений. Ключевое слово piecewise используется только при работе с методами rkf 45 и rosenbrock и позволяет выводить результат в виде кусочно-непрерывной зависимости |
| range | Диапазон с численными границами | Опцией задается диапазон изменения независимой переменной |
| relerr | Число | Предел для относительной погрешности. Опция не может использоваться при выполнении расчетов методами classical, taylorseries и bvp |
| stiff | Логический тип | Если установить значение опции равным true, то вместо используемого по умолчанию нежесткого метода rkf 45 будет вызван метод rosenbrock. Если при этом также явно задан используемый метод, то выполняется проверка на предмет его соответствия значению опции stiff |
| stop cond" | Список | Значением функции задается список условий приостановки процесса вычислений. Опция может использоваться для вызываемых по умолчанию нежесткого метода rkf 45 и жесткого метода rosenbrock |
Кроме перечисленных выше опций, общих для процедуры dsolve(), при работе с каждым конкретным методом можно использовать специфичные именно для этого метода опции. Подробнее о них читатель может узнать, обратившись к справочной системе.
Ниже показано, как следует вызывать процедуру dsolve() для численного решения дифференциальных уравнений.
В качестве первого примера рассмотрим уравнение первого порядка.
Численное интегрирование
Численное интегрирование выполняется с помощью той же самой процедуры, что и вычисление интегралов в символьном виде. Разница состоит в том, что теперь процедура int() (или Int()) сама указывается аргументом процедуры evalf(). При этом имеет место следующее правило. Если используется процедура int(), то сначала предпринимается попытка вычислить интеграл в символьном виде. Если же воспользоваться неактивной формой процедуры, т.е. Int(), то интеграл сразу будет вычисляться в численном виде. Разумеется, речь идет о тех случаях, когда процедуры сами являются параметром процедуры evalf() и для переменной интегрирования задан диапазон изменения. Параметром указанных Процедур может быть и оператор. В этом случае указывается только диапазон изменения переменной — сама переменная не указывается. .Кроме того, в процедурах Into и int() допускается использование необязательных параметров. Эти параметры описаны в табл. 7.6.
Таблица 7.6. Опции процедуры int()
| Опция | Описание |
| digits | Значением опции является целое положительное число, определяющее количество значащих цифр. Допускается задавать значение опции без указания последней. По умолчанию значение опции определяется переменной среды Digits |
| epsilon | Верхняя граница для относительной погрешности вычислений. По умолчанию определяется согласно формуле epsilon=0.5 *10Л(1-digits) |
| method | Метод вычисления интеграла. Значение может указываться без ссылки на название опции |
Первостепенное значение имеет метод, с помощью которого вычисляется интеграл. Особенно это справедливо, когда в символьном виде интеграл вычислен быть не может. Возможные значения опции method перечислены в табл. 7.7.
Рассмотрим примеры, в которых интегралы вычисляются разными методами. Для начала вычислим следующий интеграл.
Численные методы
Интерполяция методом Лагранжа Интерполяция методом Ньютона Общая задача интерполирования Встроенные процедуры Maple Процедуры пакета CurveFitting Решение уравнений Численное дифференцирование Численное интегрирование Заключительные замечания Контрольные вопросы
Интерполяция методом Лагранжа
На практике очень часто приходится иметь дело с данными, которые представлены в виде таблиц и задают зависимость одних параметров исследуемого явления от других. Задача состоит в том, чтобы по таким данным восстановить соответствующую аналитическую зависимость.
Предположим, имеется таблица значений неизвестной функции f(x) в точках х0, х,, ... х„. Другими словами, известны только значения функции в этих точках: f(x), к = 0..и. По этим значениям предстоит построить такую функцию f(х), чтобы она с приемлемой точностью аппроксимировала исходную функцию f(x) (что такое приемлемая точность — вопрос отдельный!) и ее значения в точках хк совпадали со значениями функции в этих точках (которые, кстати, называются узлами). Задача построения такой функции и называется задачей интерполирования.
К задачам интерполирования прибегают не только в случаях, когда вид функции f(x) неизвестен, но и когда известное аналитическое выражение для f(x) слишком громоздко и неприемлемо для проведения вычислительных оценок.
Как правило, при интерполировании выбирается набор базисных функций и интерполирующая функция <р(х) строится в виде линейной их комбинации. Такие базисные функции, как минимум, должны быть линейно независимы на отрезке, на котором выполняется интерполирование. Часто в качестве базисных функций выбирают ограниченный базис из набора ортогональных функций — например, классических ортогональных полиномов.
Интерполяция методом Ньютона
При интерполяции по методу Ньютона в результате получают тот же полином, что и при интерполяции Лагранжа. Причина проста и состоит в том, что в обоих случаях строят полином минимально необходимой степени, проходящий через заданные точки. Такой полином определяется однозначно и потому не зависит от способа, которым он получен. В этом смысле интерес представляет не получаемый результат, а скорее сам процесс его получения.
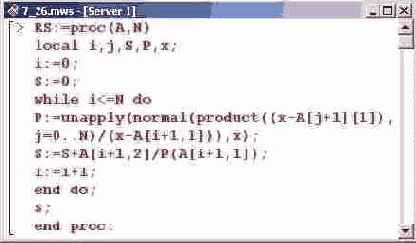
Параметрами процедуры RS() являются список А узловых точек и значений интерполируемой функции в этих точках, а также порядок N разделительной разности.
В начале процедуры инициализируются с нулевыми значениями переменные i и S. Далее следует условный оператор while. Проверяемым в этом операторе условием является неравенство i=N. Таким образом, команды из оператора цикла будут выполняться до тех пор, пока значение переменной i не превысит N. Изменение значения индексной переменной на единицу осуществляется последней командой в операторе цикла.
Контрольные вопросы
1. Какие из перечисленных ниже процедур Maple могут использоваться для выполнения полиномиальной интерполяции? Нужно ли при этом подключать специальные пакеты? а) interp(); б) Rationallnterpolation(); в) spline(); г) LeastSquares(); 2. Являются ли корректными следующие команды (В — массив базовых точек и значений функции)? Что будет происходить в каждом из перечисленных случаев? а) LeastSquares(B,x,curve=a+b*sin(Pi*x)); б) LeastSquares(В,x,curve=a+b*sin(Pi*x), params={a,b}); в) LeastSquares(В,х,curve=b*sin(Pi *x), params={b,Pi}); г) LeastSquares(B,x,curve=a+Pi*sin(x)); 3. В каком из приведенных ниже случаев будет генерироваться одно и то же случайное число А в диапазоне от 0 до 20? а) > randomize: rjiumer:=rand(0..20): A:=r_numer(); б)> randomize (20): г_пшпег:=rand(0..10): AT=r_numer(); в) > randomize(25): г numer:=rand(0..20): A7=r_numer(); г) такое число сгенерировать нельзя 4. Какая из представленных ниже процедур используется при численном решении алгебраических уравнений? a)solve(); , 6)fsolve(); ' в) dsolve(); г) pdsolve(); 5. В каком из перечисленных ниже случаев интеграл вычисляется в численном (приближенном) виде? Все ли команды корректны? a)evalf(int(x,x=0..1)); 6)int(x,x=0..1); в)evalf(lnt(x,x=0..1)); г)evalf(Int(x->x,0..l)
На заметку
Ограниченным базис называется потому, что используются не все функции этого базиса (все функции образуют бесконечное множество). По полному базису можно разложить практически любую функцию, удовлетворяющую условию квадратичной интегрируемости (интеграл от квадрата функции на данном интервале должен быть ограниченным). Однако чтобы однозначно разложить функцию по бесконечному базису, необходимо либо иметь бесконечное число условий (что, понятно, недостижимо), либо знать саму функцию (в этом случае нет необходимости выполнять интерполяцию). Поскольку функция интерполируется по конечному числу точек, используется конечный базис. В результате в общем случае выражение для функции получаем приближенное — "точное попадание" является случайностью.
Ниже рассмотрим некоторые наиболее популярные методы построения интерполяционных функций.
При интерполяции методом Лагранжа интерполяционная функция строится в виде полинома, а в качестве базисных функций выбираются степенные функции из последовательности 1, х , хг, ... х", ... . Количество таких функций определяется числом базовых точек. Таким образом, при построении интерполяционного полинома по N точкам степень полинома равна N-1. Сама интерполяционная функция L(x) ищется в виде L(х) = f(x)<*>,(*) где f(x,) есть табличные значения интерполируемой зависимости в узлах, а функции <рХх) являются полиномами степени N и равны нулю во всех узловых точках, кроме той, индекс которой совпадает с индексом функции. Другими словами, имеет место соотношение <pAx,) = s,1 > гДе < — символ Кронекера. Следовательно, можем создать процедуру, которая по базовым точкам и значениям функции в этих точках будет строить интерполяционный полином Лагранжа. Программный код процедуры lagr() приведен ниже. У процедуры всего один параметр — список с узловыми точками и значениями функции. С точки зрения Maple этот параметр является списком, элементы которого также являются списком. Данный факт отражен указанием типа параметра list (list). Будем исходить из предположения, что узловая точка и значение функции в этой точке являются списком из двух элементов (первый — узел, второй — значение функции в узле). Эти списки, в свою очередь, объединяются в общий список, образуя тем самым параметр процедуры.
На заметку
Команда sl[l] возвращает в качестве значения узловую точку из списка, выбранного в первом цикле, в то время как с помощью команды s[l] возвращается узловая точка списка, выбранного во втором, вложенном в первый, операторе цикла. После выполнения внутреннего цикла переменная Lg представляет собой не что иное, как один из базовых полиномов, по которым строится интерполяционная функция.
Переменная Lg, после выполнения внутреннего цикла, умножается на значение функции в соответствующем узле (команда si[2]) и прибавляется к переменной L, которая предварительно, в самом начале процедуры, инициализируется с начальным значением, равным нулю. По окончании выполнения внешнего цикла, в переменной L будет записан интерполяционный полином Лагранжа. В этом полиноме собираются слагаемые при соответствующих степенях аргумента (команда collect (L,x)), а результат выполнения процедуры возвращается как функциональный оператор, действие которого на аргумент состоит в построении интерполяционного полинома по данным Data. Оператор задается командой unapply(L,x). После этого процедура готова к использованию.
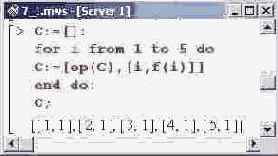
Для проверки работы последней создаем список А.
На заметку
По умолчанию процедурой rand() генерируется целое случайное число из двенадцати цифр
Затем выполняется оператор цикла, в котором переменная цикла i пробегает все значения в диапазоне от 1 до N. Для каждого значения переменной цикла список В дополняется новым элементом, который сам является списком из двух чисел и записывается в конец списка В. Узлами интерполирования являются точки с 0 по 9 включительно (в общем случае верхняя граница равна N-l), a значения функции в этих точках есть случайные числа в диапазоне от 0 до 20, и эти числа генерируются с помощью процедуры Rvalue(). В конце оператора цикла стоит двоеточие, чтобы в процессе дополнения списка В новыми элементами каждое обновленное значение переменной не выводилось на экран. После оператора цикла указана переменная В. В этом случае пользователь увидит уже окончательный список интерполяционных узлов.
По сгенерированным таким образом точкам можно построить график интерполяционной функции. Делаем это посредством ранее созданной процедуры plotl(). Результат представлен ниже.
На заметку
Если число интерполяционных точек равно n+1, то полином может иметь порядок и ниже п Это имеет место, например, в тех случаях, когда интерполируемая функция сама является полиномом степени, меньшей n
Далее предположим, что производная порядка (n+1) от интерполируемой функции на интервале интерполирования не превышает по абсолютной величине значения М . Тогда погрешность интерполирования в точке х не превышает величины. Не затрагивая вопроса о том, как выполнить оценку для производной интерполируемой функции (это зависит от конкретных рассматриваемых ситуаций и выходит за рамки тема-лоси книги), разработаем процедуру, которая будет автоматически определять погрешность интерполирования при заданном значении М. Соответствующий программный код приведен ниже.
На заметку
Предложенный выше способ определения разделительных разностей основан на определении специальной функции Р() для вычисления произведения аргументов. В общем случае число таких функций на единицу больше порядка разделительной разности. Произведение можно было бы вычислить и без вызова функционального оператора более простым способом. Поэтому приведенный программный код носит скорее иллюстративный характер и призван показать возможности и преимущества командного языка Maple.
Теперь определим оператор, с помощью которого будем строить интерполяционный полином Ньютона.
На заметку
Несовпадение индексов выше объясняется просто. Дело в том, что индексация коэффициентов начинается с нуля, а индексация элементов в списках X и У — с единицы.
Далее определяется функция L(), имеющая структуру интерполяционного полинома Ньютона. В этой функции присутствуют неизвестные пока что коэффициенты а[ j]. Чтобы найти эти коэффициенты, зададим уравнения, из которых они будут определяться. Уравнения будем записывать в качестве элементов множества EqSys, которое инициализируется как пустое. Уравнения определяются следующим образом. В операторе цикла с помощью индексной переменной 1 перебираются значения из списка X и подставляются в функцию L(), задающую полином. По определению в этих точках значения полинома должны совпадать с соответствующими элементами из списка Y. Полученные уравнения заносятся во множество EqSys.
На заметку
Для решения такой системы в среде, отличной от Maple, пришлось бы разрабатывать специальные подпрограммы.
Для того чтобы коэффициентам присвоить значения в соответствии с полученным решением, используется процедура assign(). Результат решения системы уравнений возвращается в виде множества равенств, определяющих искомые коэффициенты. Именно на это множество и ссылается переменная среды % в аргументе команды. После этого в выражении L(x) слагаемые группируются по степеням аргумента, и такое выражение возвращается как результат выполнения процедуры.
На заметку
В Maple 9 в процедуре Spline() допускается использование опции endpoints, значениями которой могут быть ключевые слова natural (значение по умолчанию), notaknot или periodic. С помощью этой опции задается тип условий на границах интервала интерполирования. В качестве значения может также указываться список, массив или матрица, определяющие характер поведения функции или ее производных на границах интервала.
На заметку
В Maple 9 процедура Polynomial interpolation () имеет опцию form, которая определяет, в каком виде будет выведен на экран интерполяционный полином. Ее возможными значениями являются ключевые слова Lagrange, monomial, Newton и power.
Однако возможности пакета этим не исчерпываются. Рассмотрим процедуру Rationallnterpolation(), которая позволяет находить интерполяционную-функцию в виде рациональной дроби, где числитель и знаменатель являются полиномами. Порядок вызова процедуры следующий. Сначала указывается список узлов и список значений функции в этих узлах. В качестве альтернативы может быть задан также один список с парами "точка—значение". Далее указывается интерполяционная переменная. На этом обязательные параметры заканчиваются. В качестве необязательных параметров могут указываться значения для опций method и degree (значения указываются так: опция, знак равенства, значение опции). Для опции method, определяющей метод обработки сингулярностей, возможны два значения: lookaround (метод "обхода" сингулярностей, используется по умолчанию) и subresultant (метод "перехода" через сингулярности). Для опции degree значение указывается в виде списка, элементы которого задают степени полиномов числителя и знаменателя соответственно. Вот как данная процедура выглядит в действии.
На заметку
В данном случае в результате выполнения команды nsol(0) выводится список, в котором указано значение точки и значение функции в этой точке. В общем случае в таком списке присутствует еще и значение для всех производных вплоть до порядка, на единицу меньшего порядка старшей производной в решаемом уравнении. Поскольку старшей производной в данном уравнении является производная первого порядка, в списке представлены только точка и значение функции в этой точке.
Выведем численные значения функции на интервале от 0.1 до 0.8 с шагом 0.1. Результат представлен ниже.
На заметку
Вычисление интегралов методом Монте-Карло основано на использовании вероятностных оценок. Например, площадь круга могла бы вычисляться так: генератором случайных чисел продуцируются точки на плоскости, попадающие во внутреннюю область квадрата с координатами вершин (1,1), (-1,1), (-1,-1), (1,-1). Затем среди этих точек подсчитывается (в процентном отношении) количество тех, которые попадают во внутреннюю область круга единичного радиуса, вписанного в этот квадрат. При большом количестве точек упомянутое процентное отношение будет одновременно определять отношение площади круга к площади квадрата. Последняя, очевидно, равна 4. Метод достаточно элегантный, но не очень точный.
Вывод, как и в случае численного дифференцирования, состоит в том, что спецификацию метода разумно выполнять только в тех случаях, когда пользователь полностью уверен в правильности своих действий.
Общая задача интерполирования
В качестве базовых интерполяционных функций можно выбрать, по большому счету, любой их набор — главное, чтобы такие функции были независимы. Причем линейной независимости функций в обычном понимании этого термина в данном случае недостаточно. Предположим, что интерполяция выполняется по узлам хо,х1,...,х„. Количество базовых интерполяционных функций должно совпадать с количеством узловых точек. Пусть это будут функции. Чтобы функции могли использоваться в процессе интерполяции, они должны быть такими, чтобы любая их линейная комбинация имела на интервале интерполяции число корней (т.е. точек, где эта линейная комбинация обращаются в нуль) по крайней мере на единицу меньше, чем число базовых узлов. Такие системы функций еще называют системами Чебышева.
Интерполяционную функцию ищем в виде Fn(x) = a0<po(x) + a,<pt(x) + ... + a,<pn(x). Коэффициенты а, находятся из тех условий, что в узловых точках значения интерполяционной функции совпадают с табулированными значениями интерполируемой функции: Fll(xl) = yi. Таким образом, имеем систему п+1 уравнений относительно п+1 неизвестного коэффициента а,. Из этих уравнений коэффициенты определяются однозначно.
Ниже представлен код процедуры, с помощью которой можно выполнять интерполяцию разными базовыми функциями.
Параметрами процедуры Mylnt() являются список базовых точек А, по которым строится интерполяционная функция, а также оператор f (), который задает общий вид базовых интерполяционных функций.
Если пользователь скопирует приведенный выше
Если пользователь скопирует приведенный выше программный код в рабочий лист Maple и несколько раз подряд выполнит его, то каждый раз он будет получать разные наборы базовых точек и, соответственно, будет видеть иную картинку
В общем случае, когда абсолютно ничего не известно об интерполируемой функции, сделать оценку для погрешности интерполяции невозможно Но такую оценку можно выполнить, если известны оценки для производных интерполируемой функции.
Погрешность при решении задачи интерполяции
Погрешность при решении задачи интерполяции может быть вызвана следующими причинами Во-первых, существует погрешность, связанная с неточностью заданных узловых точек и значений интерполируемой функции в этих точках Во-вторых, погрешность возникает при вычислениях из-за округления чисел с плавающей точкой Наконец, существует погрешность вследствие замены исходной интерполируемой функции интерполяционным полиномом Здесь и далее речь идет именно о такой погрешности
Предположим, что число узловых точек, по которым выполняется интерполяция, равно п+1. Это автоматически означает, что порядок интерполяционного полинома равен п.
и заканчивая индексом N. Число
Элементы списка С нумеруются, начиная с индекса 1 и заканчивая индексом N. Число интерполяционных точек, таким образом, равно N. Порядок интерполяционного полинома равен N-1. Поэтому оценка М является верхней границей на интервале интерполирования для производной порядка N. Ведь порядок производной должен совпадать с числом точек и быть на единицу больше, чем порядок интерполяционного полинома. Отсюда в выражении для погрешности и далее для порядка производной указано N, а не N+1.
Результат выполнения процедуры оформляется в виде строки. Строка создается процедурой объединения cat(). Параметрами процедуры указаны базовые текстовые фразы вперемежку с командами преобразования численных выражений в строки. В последнем случае использована процедура convert () с опцией string.
Здесь еще раз хочется напомнить,
Здесь еще раз хочется напомнить, что при интерполяции функции полиномом последний не зависит от способа его получения. В этом смысле, что полином Ньютона, что Лагран-жа — все едино. Полином один и тот же. Название характеризует только способ, которым этот полином был получен.
Процедура newton() имеет только один параметр, который представляет собой список с узловыми точками и значениями функции.
Не следует забывать, что нижняя
Не следует забывать, что нижняя граница изменения индексной переменной равна О, в то время как индексация элементов списков начинается с 1.
Полученная в результате система решается относительно неизвестных коэффициентов, для чего используется процедура solve ().
В отличие от предыдущих случаев,
В отличие от предыдущих случаев, в том числе и процедуры newtonf), где результат процедуры задавался как действие, в процедуре newton2() результатом является выражение. Здесь переменная интерполирования указывается параметром процедуры.
Определяем теперь базовые списки с узловыми точками и значениями функции.
Приведенная выше система функций часто
Приведенная выше система функций часто используется для интерполирования периодических функций. Перечисленные функции в совокупности периодичны с периодом 2л. Поскольку в данном случае функция интерполируется на сегменте от -2 до 2, т.е. длина сегмента равна 4 (что меньше указанного периода), интерполяция возможна. В противном случае пришлось бы выполнять замену переменных.
Теперь строим интерполяционную функцию.
В качестве четвертого параметра может
В качестве четвертого параметра может быть указано любое целое положительное число, не только в диапазоне от 1 до 4. Просто для этих чисел существует альтернативный вызов через текстовую опцию. Например, командой spline(X,У,х,5) можно выполнить интерполяцию рассмотренной выше функции полиномами пятой степени и т.д.
Интерполяция полиномами четвертой степени все той же функции выглядит следующим образом.
Если аппроксимирующая функция получена по
Если аппроксимирующая функция получена по методу наименьших квадратов, то никакой гарантии в том, что она проходит не то что через все, а хотя бы через одну базовую табличную точку, нет. В этом смысле метод наименьших квадратов принципиально отличается от рассмотренных ранее способов построения интерполяционной функции. Именно поэтому функцию, получаемую при использовании метода наименьших квадратов, будем называть не интерполирующей, аппроксимирующей.
Использование процедуры LeastSquares () позволяет сразу получить желаемый результат. Для этого следует ввести соответствующую команду, указав ее параметрами либо два списка с узлами и значениями функции, либо один с элементами-списками, в которых первый элемент является узловой точкой, а второй — значением функции в этой точке. После этого указывается название переменной. Если на этом остановиться, то после выполнения процедуры результат будет возвращен в виде линейной зависимости по аргументу. Ниже в табл. 7.2 представлено детальное описание опций, которые, помимо обязательных аргументов, могут использоваться вместе с процедурой LeastSquares().
Таблица 7.2. Опции процедуры LeastSquares ()
| Опция | Описание |
| curve | Определяет общий вид аппроксимирующей кривой. Зависимость должна быть линейной по параметрам! На зависимость функции от аргумента ограничения не накладываются |
| parame | Может использоваться в тех случаях, когда явно задана опция curve. Значение данной опции задается в виде списка переменных, которые следует считать параметрами оптимизации. Если значение не задано, параметрами оптимизации считаются все переменные, отличные от той, что указана в параметрах процедуры как независимая |
| weight | Определяет весовые множители. Ее значением может быть список из неотрицательных чисел, а число элементов списка должно строго соответствовать числу узловых точек |

Чтобы задача не была слишком простой, внесем некий элемент случайности. Для этого воспользуемся генератором случайных чисел. Табулируем значения функции так: после вычисления значения функции в узле согласно приведенной выше формуле, к этому значению будем добавлять случайное число в диапазоне от 0 до 1. Таким образом, табличные значения функции будут иметь погрешность примерно 10 процентов. Ниже показана группа команд, в которой инициализируется генератор случайных чисел (численный параметр указан для того, чтобы при каждом новом запуске генерировалась одна и та же последовательность чисел) и определяется процедура RV(), генерирующая случайное число в диапазоне от 0 до 100. Затем переменная В заполняется парами значений узлов и функции (с учетом погрешности), и конечное ее значение отображается в области вывода. При заполнении списка В значения функции преобразуются в формат чисел с плавающей точкой. Кроме того, поскольку процедура RV() генерирует случайное число в диапазоне от 1 до 100 (а нужно, чтобы оно было в диапазоне от 0 до 1), это число делится на 100.
обязательно следует указывать значение для
Выше при вызове процедуры LeastSquares() обязательно следует указывать значение для опции params. Если этого не сделать, то константа Pi в аргументе синуса будет интерпретироваться как параметр оптимизации. Поскольку функция по параметру нелинейна, ничем хорошим это не закончится (появится сообщение об ошибке).
Построим графики для полученных зависимостей. Вместе с графиками квадратами отобразим точки, по которым выполнялась оптимизация.

Первые две штрихованные кривые мало чем отличаются, в то время как третья (сплошная линия) достаточно точно отображает исходную зависимость. Однако чтобы в общем случае методом наименьших квадратов эффективно строить аппроксимирующие функции, необходимо знать вид аппроксимируемой функциональной зависимости.
а выражение, то решаться будет
Если первым аргументом процедуры fsolve)) указано не непосредственно уравнение (равенство), а выражение, то решаться будет уравнение, получаемое путем приравнивания этого выражения к нулю.
Для поиска всех корней, в том числе и комплексных, при вызове процедуры указываем опцию complex.
Перед тем, как выделять функциональную
Перед тем, как выделять функциональную зависимость процедурой unapply(), указанное параметром процедуры выражение f £ преобразуется в формат представления чисел с плавающей точкой. Для этого используется процедура evalf (). Последнее не является необходимым, но рекомендуется. Причина заключается в том, что при вычислении логических значений работать в формате представления чисел с плавающей точкой намного удобнее. Кроме того, это позволяет избежать ошибок, связанных с невозможностью аналитического исследования громоздких выражений на предмет их знака.
После определения всех необходимых параметров проверяется знак произведения значений функции на границах диапазона. Если произведение больше нуля, то, значит, функция на границах имеет значения одного знака и метод вычисления корня путем деления интервала пополам применен быть не может. В этом случае выводится сообщение соответствующего содержания. В противном случае, если произведение значений функции на границах интервала меньше нуля (ситуацию, когда такое произведение равно нулю, рассмотрим отдельно), выполняется условный оператор while. Проверяемое при этом условие состоит в том, что длина интервала превышает погрешность и одновременно значение функции в центре этого интервала не равно нулю.
с является центром интервала, станет
О том, что точка х= с является центром интервала, станет известно после выполнения первой команды в операторе while. Именно там переменной с будет присвоено значение. Как правило, в таких ситуациях при работе с иными программными пакетами возникает ошибка. Но только не в Maple! Даже если переменной не присвоено значение, выражение для функции в точке будет вычислено в символьном виде. Поскольку тождественно нулю оно не равно, процедура должна работать корректно. Однако для страховки можно разместить команду инициализации переменной с до начала выполнения оператора while, например сразу после инициализации локальных переменных а и Ь, а команду присваивания нового значения этой переменной перенести в конец операторного блока.
До тех пор, пока условие не будет выполнено, интервал уменьшается на каждом шаге в два раза. Новые границы выбираются в зависимости от знака значения функции в центре интервала и на его границах.
Наконец, рассматривается ситуация, когда произведение значений функции на границах начального интервала равно нулю. В этой ситуации проверяется на равенство нулю значение функции в точке х=а, и если это значение равно нулю, оно и возвращается в качестве решения. В противном случае решением является граничная точка х=b.
в том случае, если обе
Согласно определению процедуры, в том случае, если обе границы первоначального интервала одновременно являются корнями, возвращен будет тот, который соответствует первой (нижней) указанной границе диапазона.
Полученное значение для корня (переменная с) преобразуется в формат числа с плавающей точкой, а результат возвращается в виде равенства перемевиа&зиачение. Ниже приведены результаты использования разработанной процедуры для исследования полиномиального выражения.
Результатом решения уравнения является, как
Результатом решения уравнения является, как известно, равенство. Если процедуру unapply() применить к равенству, то получим оператор, действие которого на аргумент состоит в восстановлении равенства, правда, уже с переменной, указанной аргументом оператора. Это замечание важно для понимания результата выполнения команд, приведенных ниже.
Выведем значения функции, полученной в качестве точного решения.
Процедуры пакета CurveFitting
В Maple есть пакет, который предназначен специально для выполнения различного рода аппроксимаций. Речь идет о пакете CurveFitting. Ниже
описываются основные функции и процедуры, которые будут доступны после подключения данного пакета.
Для выполнения сплайн-интерполяции в пакете CurveFitting предлагается процедура Spline (), действие которой практически полностью аналогично встроенной процедуре spline(), однако по сравнению с последней данная процедура имеет более свободный синтаксис вызова. Причем один из способов указания аргументов такой же, как и у процедуры splinef). Исключение составляет четвертый необязательный параметр. В данном случае степень базового полинома указывается так: значение, где в качестве значение следует ввести целое положительное число (по умолчанию принимается равным 3). Еще один способ вызова подразумевает указание вместо первых двух параметров (списка узловых точек и списка значений функции в этих точках) одного списка с элементами "точка-значение". Другими словами, аргументом процедуры можно использовать список из списков, как это было в разработанной ранее процедуре lagr(). Правда, та процедура действовала на интерполяционную переменную, являясь функциональным оператором. В этом случае интерполяционная переменная указывается в качестве аргумента процедуры. На этом, пожалуй, особенности процедуры Spline() исчерпываются. Ниже приведены примеры ее использования.
Решение уравнений
Встроенные функции Maple при аналитическом решении уравнений исключительно эффективны. При решении уравнений в численном виде это справедливо вдвойне. В последнем случае может быть полезна процедура fsolveQ. Первым ее параметром указывается решаемое уравнение или система уравнений, после чего следует ввести переменную, относительно которой решается уравнение, или множество переменных для системы уравнений. Кроме того, с процедурой допускается использование некоторых опций. Эти опции описаны ниже в табл. 7.3.
Таблица 7.3. Опции процедуры f solve ()
| Опция | Описание |
| avoid | В качестве значения этой опции указывается список равенств, определяющих те значения переменной (или переменных), которые следует игнорировать при поиске решения |
| complex | Если указать эту опцию, поиск решений будет осуществляться на множестве комплексных чисел |
| fulldlgits | Данная опция позволяет поддерживать высокую точность округления при промежуточных расчетах |
| maxsols | Эта опция используется при работе с полиномами. Ее значением указывается число определяемых процедурой корней. В качестве корней выбираются наименьшие |
Кроме перечисленных опций, в процедуре можно указывать интервал, на котором выполняется поиск решений. Сделать это можно двумя способами. В первом случае просто указывается диапазон, во втором — переменная и, после знака равенства, диапазон ее изменения. При поиске решения исследуются и граничные точки диапазона. Ниже приведены примеры использования процедуры fsolve() для нахождения корней полинома х(х -2)(2 +4). Прежде всего, задаем следующую функцию.
Решение задачи

Основу процедуры составляют два вложенных цикла. В рамках первого цикла переменная si пробегает значения из списка-параметра процедуры. Такими значениями являются списки, определяющие точку и значение функции. Сначала переменная Lg устанавливается равной 1, после чего, используя второй цикл и переменную цикла s, перебираются элементы списка Data, и если выбранный элемент не совпадает с текущим элементом si, переменная Lg умножается на s[l]).
Если теперь по заданным точкам

Если теперь по заданным точкам строить интерполяционную функцию, получим следующий полином третьей степени.
согласно ее определению, является оператором,

Внимание!
Поскольку процедура lagr(), согласно ее определению, является оператором, она должна действовать на аргумент, который и является переменной интерполирования.
Процедура определена таким образом, что точки интерполирования не обязательно указывать в порядке их естественного следования. Например, можем создать список А1, который получается из списка А путем перестановки элементов.
Как несложно проверить, интерполяционный полином

Как несложно проверить, интерполяционный полином при этом не меняется:
Ниже определим процедуру, которая будет

Ниже определим процедуру, которая будет отображать в области вывода график для интерполяционного полинома Лагранжа вместе с базовыми точками, по которым выполняется интерполяция.
Параметрами процедуры plotl() определим список базовых интерполяционных точек и переменную интерполирования. Код процедуры приведен ниже.
в теле процедуры используются для

Локальные переменные а и b в теле процедуры используются для определения нижней и верхней границ области интерполирования соответственно Значения обеих переменных инициализируются равными первой указанной в списке-параметре процедуры интерполяционной точке (ссылка В [1,1]— первый элемент из первой пары "точка-значение" списка В). После этого перебираются все интерполяционные точки (ссылка с[1]), и если среди них встречается значение, меньшее текущего значения а, — оно присваивается этой переменной. Значение переменной b переопределяется в том случае, если выбранная точка имеет значение, большее текущего значения Ь. В результате выполнения цикла в переменной а будет записана самая левая точка, в переменной b — правая. Наконец, вызывается процедура отображения двухмерной графики plot(), в которой отображаемыми функциями указаны интерполяционный полином Лагранжа, построенный по точкам списка В, а также сами эти точки. Ниже приведен пример вызова разработанной только что процедуры.
Аппроксимация зависимостей интерполяционными полиномами Лагранжа

Аппроксимация зависимостей интерполяционными полиномами Лагранжа наиболее эффективна, когда интерполируемая функция сама является полиномом. В этом случае, если взять достаточное количество базовых точек, можно добиться абсолютного совпадения. Однако подобные ситуации случаются не часто, и вопрос о погрешности, возникающей вследствие интерполяции, представляется актуальным. Что касается непосредственно метода Лагранжа, то на границах области интерполирования соответствующие полиномы могут в значительной степени отклоняться от прямой, соединяющей соседние точки. Последнее далеко не всегда приемлемо. В качестве примера рассмотрим "случайный" полином, т.е. созданный по базовым точкам, заданным генератором случайных чисел. Ниже приведен код для генерирования значений интерполируемой функции и результат его выполнения. Все команды объединены в одну исполнительную группу, так что для их выполнения достаточно щелкнуть кнопкой мыши на любой команде группы и нажать <Enter>. Результат выполнения в области вывода приводится сразу для всей группы.
в группе является команда randomize

Первой в группе является команда randomize инициализации генератора случайных чисел. После этого в качестве пустого списка инициализируется переменная в. Значение переменной N, определяющей количество узлов, по которым будет строиться интерполяционный многочлен Лагранжа, установлено равным 10. Далее посредством команды rand(0..20) определяется процедура Rvalue(), которая будет генерировать случайное число в диапазоне от 0 до 20.
Как несложно заметить, на границах
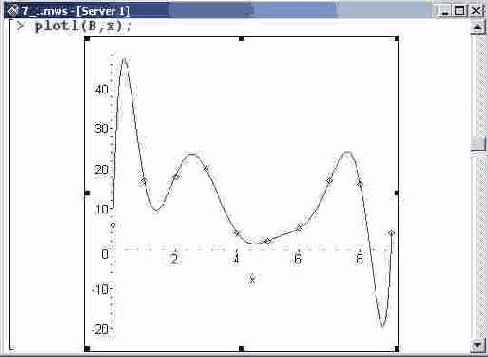
Как несложно заметить, на границах области интерполирования отклонения полинома действительно существенны.
имеет три параметра. Первым параметром

Процедура ErEst() имеет три параметра. Первым параметром является базовый список с интерполяционными точками. Второй и третий параметры — переменная интерполирования и оценка для производной интерполируемой функции соответственно.
Первой командой в теле процедуры определяется количество элементов в списке С. Для этого вызывается процедура vectdim() из пакета linalg. Полученное в результате число присваивается в качестве значения переменной N. Далее переменной S присваивается произведение, которое формируется процедурой product(). Множители в произведении— это разность переменной интерполирования и значения узловой точки. Ссылки на узловые точки выполнены в виде C[i][1] через индексную переменную!, которая пробегает значения от 1 до N. Погрешность интерполяции, таким образом, не превышает модуль (процедура abs()) величины MS/N1.
Если третьим параметром указать число,

Если третьим параметром указать число, погрешность также будет представлена числом. Посмотрим, что произойдет, если в качестве второго параметра указать узловую точку.
в том, что погрешность равна

Ничего удивительного в том, что погрешность равна нулю, нет. Ведь в узловой точке, по определению, значение интерполяционного полинома точно совпадает со значением функции.
Нетрудно понять, что погрешность интерполирования зависит не только от интерполируемой функции, но и от выбора интерполяционных точек. Проиллюстрировать это можно следующим примером. Определим тригонометрическую функцию.
После этого создаем два списка.

После этого создаем два списка. В каждом из этих списков табулируем значения функции по пяти узловым точкам. Однако узловые точки в каждом случае выбраны по-разному.
В первом случае выбираем равноудаленные узлы.
Во втором случае узлы выбираются
Во втором случае узлы выбираются согласно формуле xi=(i-l/i), а индексная переменная i пробегает значения от 1 до 5.
Теперь на одном рисунке отобразим

Теперь на одном рисунке отобразим все три графика: для интерполируемой функции и двух интерполяционных полиномов для каждого набора точек. Точки из первого набора, определяемого списком С, обозначены квадратами, а из второго набора, определяемого списком С1, — кругами.
Как видно из рисунка, интерполяционные

Как видно из рисунка, интерполяционные полиномы весьма далеки от совершенства. Полином по первому множеству вообще представляет собой прямую. Поэтому естественным образом возникает вопрос о том, как следует выбирать интерполяционные точки, чтобы полином наиболее адекватно описывал интерполируемую функцию. Понятно, что если исходная функция неизвестна и узловые точки заданы a priori, постановка такой задачи не имеет смысла. Однако, как уже отмечалось, часто нужно интерполировать известную функцию. В этом случае задача выбора узловых точек на интервале интерполирования полностью ложится на пользователя.
Не вдаваясь в детальный теоретический анализ, сформулируем сразу ответ (читателей, интересующихся данной проблемой, отсылаем к специальной литературе). Состоит он в том, что нам понадобится вычислить нули ортогональных полиномов Чебышева. Зачем это делается, будет объясняться по ходу изложения материала.
В главе 3 об ортогональных полиномах Чебышева первого рода речь уже велась. Можно, разумеется, использовать встроенную команду для вызова соответствующего полинома. Однако поскольку способ их определения достаточно прост, зададим собственную функцию, зависящую от двух аргументов: индекса полинома и непосредственно полиномиальной переменной.
Прежде чем искать нули полиномов,

Прежде чем искать нули полиномов, изменим значение переменной среды _EnvAllSolutions. Это нужно для того, чтобы при решении соответствующего уравнения искались все решения.
Теперь находим нули полинома Чебышева

Теперь находим нули полинома Чебышева первого рода индекса n.
Решение представлено

Решение представлено через переменную среды _Z1, которая в области вывода сопровождается тильдой. Это значит, что на переменную наложены ограничения. Чтобы узнать, каким условиям эта переменная должна удовлетворять, воспользуемся процедурой about().
Перевод содержимого области вывода гласит,

Перевод содержимого области вывода гласит, что исходная переменная _Z1 переименована в Z1" и предполагается, что это целое число.
Теория говорит о том, что для построения оптимального полинома, который при прочих неизменных условиях будет аппроксимировать функцию на интервале от -1 до 1 с наименьшей погрешностью (наименьшая верхняя граница для погрешности), в качестве базовых узлов следует взять нули полинома Чебышева порядка, который равен числу узловых точек. Другими словами, если базовый полином строится по 10 точкам, то и полином следует брать с индексом 10. Если интерполяция выполняется на интервале (а,Ь), отличном от интервала (-1,1), то узловые точки все равно выражаются через нули указанного полинома согласно формуле хя =((Ь-а)со&{(2т+1)n/2n)+(Ь + а))/2.
Количество нулей полинома совпадает с его порядком. Чтобы перебрать все эти нули, достаточно предположить, что переменная среды принимает значения от 0 до n-1, где n — порядок полинома. Ниже приведен код процедуры, которой выполняется вычисление базового узла с индексом m на интервале (а,Ь) при общем количестве узлов n.
В качестве интерполируемой возьмем функцию

В качестве интерполируемой возьмем функцию Бесселя нулевого порядка.
в качестве пустого списка инициализируется

Ниже в качестве пустого списка инициализируется переменная Fp. Далее вычисляются узловые точки (переменная X) и значения интерполируемой функции в этих точках (переменная Y), после чего эти данные заносятся в список Fp. Стоит обратить внимание на то, что как точки, так и значения функции, вычисляются в формате чисел с плавающей точкой. Весь описанный блок команд размещен ё одной исполнительной группе. В самом конце этой группы указана команда вывести окончательное значение списка Fp.
Теперь по этим базовым точкам

Теперь по этим базовым точкам можно построить интерполяционный полином. На графике, представленном ниже, показана исходная функция, точки интерполяции и интерполяционный полином.
Можем получить выражение для представленного

Можем получить выражение для представленного выше на рисунке полинома.
Поскольку элементы списка Fp, по

Поскольку элементы списка Fp, по которому строился полином, определялись в формате числа с плавающей точкой, в таком же виде представлены и коэффициенты интерполяционного полинома.
Решение задачи
в первой узловой точке. Далее

Локальная переменная L инициализируется со значением А[1][2]. Это значение интерполируемой функции в первой узловой точке. Далее переменной Ямх присваиваем в качестве значения длину списка А. С помощью оператора цикла, согласно формуле для интерполяционного полинома, формируем соответствующее выражение. В этом операторе, кроме прочего, вызывается и разработанная выше процедура определения разделительных разностей RS(). Наконец, собираем слагаемые при соответствующих степенях аргумента (команда collect(L,x)), и для этого выражения вычисляем функциональный оператор (процедура unapply()), который и возвращается в качестве результата. Теперь процедуру можно использовать.
Для проверки работы процедуры построим интерполяционный полином по списку, который уже использовался ранее для построения интерполяционного полинома Лагранжа.
Легко заметить, что этот полином

Легко заметить, что этот полином полностью совпадает с построенным ранее. Ниже приведен пример вычисления еще одного полинома. В этом случае для интерполяционной переменной выбрано другое название.
Для построения интерполяционного полинома методом

Для построения интерполяционного полинома методом Ньютона можно было поступить несколько иначе, благо возможности Maple позволяют это сделать. Итак, будем искать интерполяционный полином в виде L(x) = ao+(x-xo)al+... + (x-xB)...(x-x,_,)a,. Коэффициенты а, нужно определить из тех условий, что в узловых точках полином принимает известные значения. Эти коэффициенты, по сути, являются разделительными разностями, о которых речь шла ранее. Однако здесь для нахождения коэффициентов воспользуемся уникальными возможностями Maple. Для этого создадим процедуру newton2(). Параметры процедуры определим несколько отличным от предыдущих случаев способом. Первые два параметра — списки X и Y с узловыми точками и значениями интерполируемой функции в этих точках. Третьим параметром является переменная интерполирования.
N определяется как такая, что
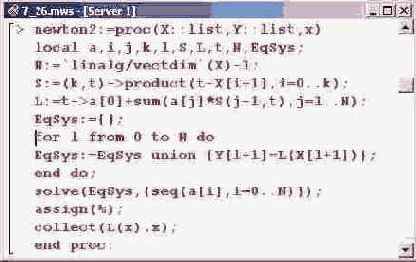
Локальная переменная N определяется как такая, что на единицу меньше числа элементов в списке X. Переменная S определяется как функция двух переменных: индекса к и аргумента t и представляет собой произведение, которое умножается затем на коэффициент с индексом к+1.
как неоднократно отмечалось, при использовании

Получаем вполне ожидаемый результат.
Поскольку, как неоднократно отмечалось, при использовании метода Ньютона получаем тот же полином, что и при интерполяции Лагранжа, справедливыми остаются все замечания, касающиеся точности интерполяционного полинома и оптимального выбора узловых точек. Здесь на подобных вопросах останавливаться не будем.
Само собой разумеется, что интерполирование полиномами не является единственно возможным способом выполнения интерполяции. Рассмотрим иные методы.
в самом начале процедуры задается

Исключительно в целях наглядности в самом начале процедуры задается два массива — узловых точек х и значений функции в этих точках у. Массивы определяются исходя из данных списка А. Переменная п инициализируется со значением, на единицу меньшим числа элементов списка А. В этом случае нумерация узлов начинается с индекса 0. Далее с помощью оператора цикла переменной s присваивается значение, структура которого совпадает со структурой искомой интерполяционной функции. В этом выражении коэффициенты a[i] являются неизвестными переменными, которые следует определить.
Используя выражение s в качестве основы, переменная L определяется как оператор, действие которого на аргумент t эквивалентно вычислению данного выражения.
На следующем этапе в процедуре определяется система уравнений eqsys, из которой будут искаться неизвестные коэффициенты разложения. Система поочередно дополняется уравнениями, которые фиксируют равенство значений интерполяционной функции L() заданным массивом у табличным значениям интерполируемой функции в узловых точках. Система решается относительно коэффициентов а[к], и полученные в качестве решения значения присваиваются этим коэффициентам (команда assign(%)). Результатом процедуры возвращается оператор L().
Проверим, как работает процедура. Для этого зададим следующий список.
В переменную L1 запишем интерполяционную

В переменную L1 запишем интерполяционную функцию (полином), построенную по степенным функциям.
В качестве базовых интерполяционных функций

В качестве базовых интерполяционных функций можно взять ортогональные полиномы. Например, рассмотрим полиномы Чебышева первого рода, которые, как известно, задаются следующим образом.
Результат интерполирования по этим полиномам

Результат интерполирования по этим полиномам запишем в переменную L2.
На первый взгляд кажется, что

На первый взгляд кажется, что получено новое, отличное от Ы, выражение, но это не так. Убедиться в последнем можно, упростив его.
в этом нет, ведь полиномы

Ничего удивительного в этом нет, ведь полиномы — есть полиномы, даже если это полиномы Чебышева.
Еще один класс функций, представляющих особый интерес, — тригонометрические функции. Рассмотрим следующую систему.
в качестве результата возвращается целая

На заметку
Командой iquo(n,m) в качестве результата возвращается целая часть отделения п на ш, в то время как irem(n,m) есть остаток от целочисленного деления n на m.
Чтобы представить себе, что же за система функций задается оператором F(), рассмотрим такую последовательность.
что это набор тригонометрических функций

Видим, что это набор тригонометрических функций (чередующиеся синусы и косинусы), используемых, корме прочего, при выполнении разложений в ряд Фурье.
в результате выражение достаточно громоздко,

Полученное в результате выражение достаточно громоздко, поэтому преобразуем его, перейдя к формату представления чисел с плавающей точкой.
о том, что нет такой

Помня о том, что нет такой формулы, которая была бы нагляднее картинки, построим две интерполяционные функции — по полиномам (L1) и тригонометрическим функциям (L3).
Сплошная линия для полиномиальной интерполяции,
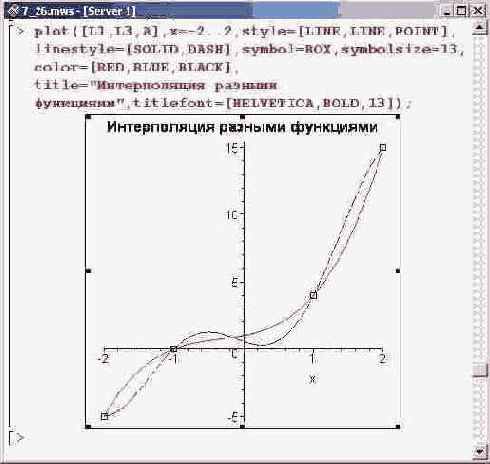
Сплошная линия для полиномиальной интерполяции, штрихованная — для интерполяции тригонометрическими функциями.
Видим, что функции ведут себя практически одинаково. Однако между такими интерполяционными функциями есть существенная разница, о которой следует помнить: при интерполяции степенными функциями, если выйти за пределы области интерполирования (в этом случае имеем дело с задачей экстраполяции), полином, в конечном счете, стремится к бесконечности, тогда как при интерполяции тригонометрическими функциями получаем ограниченную, периодичную интерполяционную функцию.
После этого можно вызвать процедуру

Таблица 7.1. Табулированные значения для интерполируемой функции
| Узловая точка | Значение функции |
| -2 | 36 |
| -1 | 48 |
| 0 | 30 |
| 1 | 0 |
| 3 | 96 |

Стоит заметить, что в качестве результата процедурой interp() возвращается выражение, а не оператор, как это было выше при разработке процедуры построения интерполяционного полинома Лагранжа.
Еще один достаточно популярный способ интерполяции состоит в следующем. На каждом интервале между соседними узловыми точками интерполируемая функция представляется в виде полинома. Но в отличие от, скажем, интерполяции Лагранжа, где один и тот же полином используется для всех точек, в данном случае на каждом интервале полином свой. Кроме равенства интерполяционной функции в узлах табличным значениям функции интерполируемой, на первую накладывается еще и условие непрерывности производных до порядка, на единицу меньшего, чем степень интерполяционных полиномов. Подобный тип интерполяции называется интерполяцией сплайнами, или сплайн-интерполяцией. Наибольшей популярностью пользуется интерполяция кубическими сплайнами.
В Maple для выполнения интерполяции сплайнами может быть использована процедура spline (). Процедура имеет три обязательных параметра. Первые два — это списки с узловыми точками и значениями функции соответственно. Третьим параметром указывается переменная интерполирования. Если четвертый необязательный параметр не указан, то интерполяция будет выполняться кубическими сплайнами, т.е. для "сшивки" узловых точек будут использоваться полиномы третьей степени. Например, если параметрами процедуры указать ранее рассмотренные списки, табулирующие значения функции в узловых точках, получим такой результат.
может быть либо одно из

Четвертым параметром процедуры spline () может быть либо одно из зарезервированных ключевых слов из набора linear (интерполяция линейными зависимостями), quadratic (интерполяция параболами), cubic (кубический сплайн), quartic (интерполяция полиномами четвертой степени), либо целое неотрицательное число, определяющее степень интерполяционного полинома. Причем указание числа от 1 до 4 эквивалентно использованию перечисленных текстовых опций, согласно того порядка, как они были представлены выше.
Выражения достаточно громоздки. Посмотрим, что
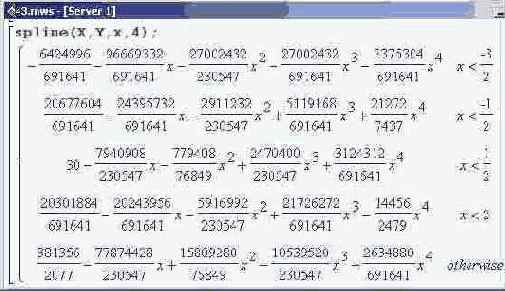
Выражения достаточно громоздки. Посмотрим, что будет, если использовать в качестве сплайн-полиномов линейные зависимости.
с предыдущим случаем, здесь получен
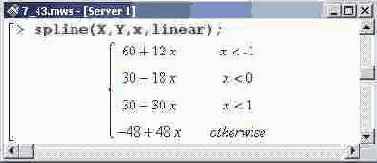
По сравнению с предыдущим случаем, здесь получен более простой результат. Однако простота — далеко не всегда значит эффективность. В этом несложно убедиться, если построить графики для интерполяционных функций, получаемых при сплайн-интерполяции полиномами разных степеней.
интерполяция является достаточно грубой. По

Очевидно, что линейная сплайн- интерполяция является достаточно грубой. По большому счету, это просто соединение интерполяционных точек линиями. Такой тип интерполяции используется крайне редко. Что касается использования полиномов прочих степеней, начиная со второй, то визуально особой разницы между ними (во всяком случае в данном примере) нет. Однако не следует забывать, что степень сплайн-полиномов определяет гладкость полученных кривых. Это важно особенно в тех случаях, когда от полученных в результате интерполяции функций следует брать производные. В этом смысле полиномиальная интерполяция по сравнению со сплайн-интерполяцией обладает тем преимуществом, что и интерполяционный полином, и производные от него однозначно являются функциями непрерывными и гладкими. Поэтому интересно сравнить результаты интерполяции полиномом и сплайн-интерполяции. Для этого построим графики соответствующих интерполяционных функций.
Можно видеть, что все три

Можно видеть, что все три графика (сплайны третьей и четвертой степени, а также интерполяционный полином четвертой степени) практически совпадают, особенно в левой части рисунка. Правда, интерполяционный полином является более гладкой функцией по сравнению с первыми двумя. При этрм у читателя может возникнуть вопрос: почему интерполяционный полином, степень которого равна четырем, не совпадает со сплайн-функцией, построенной на основе полиномов четвертой степени? Ответ следует искать в тех условиях, из которых определяется сплайн-функция. Так, при выполнении сплайн-интерполяции полиномами степени m по п+1 точкам задействовано п сплайн-полиномов. В каждом из этих полиномов следует определить по т+1 коэффициенту, и всего получаем, таким образом, n (m+1) неизвестных коэффициентов. Равенство интерполяционной функции в узловых точках табличным значениям задает п+1 условий на неизвестные коэффициенты. Кроме того, на внутренних узлах (их всего п-1) предполагается непрерывность производных до порядка т-1 включительно, что дает, вместе с непрерывностью самой функции, (n-l+(m-l)(n-l))=m(n-l) условий. Таким образом, на n(m+l) неизвестных коэффициентов накладывается (m(n-l)+(n+l))=(n(m+l)-(m-l)) условий. Этого, разумеется, мало — необходимо еще т-1 условий. Их, как правило, получают, требуя равенства нулю соответствующего числа старших непрерывных производных на границах области интерполирования. Это так называемый естественный выбор дополнительных условий. В принципе, с математической точки зрения, их можно выбирать произвольным образом — в зависимости от решаемой задачи. В частности, условия эти можно подбирать так, чтобы при интерполяции сплайнами степени п в результате получался интерполяционный полином Лагранжа.
Решение задачи

Практически те же замечания можно

Практически те же замечания можно отнести и к процедуре интерполирования полиномами Polynomiallnterpolation(), предлагаемой в пакете CurveFit-ting. От встроенной процедуры interp() эта отличается возможностью использования в качестве аргументов либо двух списков, либо одного — в полной аналогии с процедурой Spline (). Вот пример ее вызова.
Как видим, результат один

Как видим, результат один и тот же.
Чтобы сравнить разные способы интерполирования,

Чтобы сравнить разные способы интерполирования, построим графики соответствующих интерполяционных функций.
Интервал для отображения графиков не

Интервал для отображения графиков не случайно указан до 1, а не до 3, как можно было бы предположить. Дело в том, что в последнем случае разницу между интерполяционными функциями заметить вообще невозможно. Отсюда напрашивается вывод, что выбор той или иной процедуры для построения интерполяционной функции — вопрос сугубо индивидуальный и заранее, до постановки задачи, решен быть не может.
Наконец, процедура LeastSquares() из пакета CurveFitting, которую здесь рассмотрим, позволяет аппроксимировать табулированную функцию, используя метод наименьших квадратов. Метод используется, как правило, в тех случаях, когда число подгоночных параметров (тех параметров, которые могут выбираться пользователем) существенно меньше числа базовых табличных точек. Идея метода состоит в том, чтобы найти такие значения для параметров аппроксимирующей функции, что ее отклонение от табличных значений в узловых точках было бы минимальным. Для этого вводят функцию где {а} — набор параметров аппроксимирую-щей функции — узловые точки и значения аппроксимируемой функции в этих точках соответственно; а <», — весовые множители, которые обычно выбираются равными единице. Задача состоит в том, чтобы за счет параметров {а,} минимизировать записанную выше функцию Ща,}). Общий метод решения заключается в нахождении частных производных от этой функции по каждому из параметров, после чего полученные выражения прирйвииваются к нулю, такая система решается и полученные в качестве ее решения точки исследуются на экстремум.
Теперь по базовым точкам выполним

Теперь по базовым точкам выполним аппроксимацию. Сначала воспользуемся линейной зависимостью, предлагаемой по умолчанию.

В пределах погрешности, с которой определялись базовые точки, параметры определены совсем не плохо.
Если для поиска корней указать

Если для поиска корней указать диапазон 0..1, то корень, соответствующий граничной точке диапазона, будет определен так.
Решение задачи

Однако очень часто приходится не

Однако очень часто приходится не просто искать корни уравнений, а еще и демонстрировать умение создавать соответствующие процедуры для их определения. В качестве примера рассмотрим процедуру, в рамках которой вычисление корней уравнения вида f(x) = 0 осуществляется методом половинного деления интервала. Суть метода состоит в следующем. Для поиска решения выбирается начальный интервал, на котором будет выполняться поиск решения. Поиск осуществляется, если функция f(x) на границах интервала принимает значения разных знаков. В случае непрерывной функции данный факт является гарантией того, что на интервале имеется по крайней мере один корень уравнения. Далее определяется середина интервала, а также значение функции в этой точке. Данная срединная точка становится новой граничной точкой интервала — в эту точку смещается та граница интервала, для которой знак функции совпадает со знаком функции в срединной точке. После этого для нового интервала выбирается центральная точка и т.д. Таким образом, на каждом шаге интервал, содержащий корень уравнения, уменьшается в два раза. Процесс продолжается до тех пор, пока длина интервала не станет меньше погрешности, с которой следует вычислить корень. Ниже приведен код процедуры DoublDivf), согласно которой находятся корни выражения ff. Переменная, относительно которой ищутся корни, а также интервал определяются равенством xint. Погрешность задается параметром epsilon.
Основная часть кода данной процедуры

Основная часть кода данной процедуры нужна для отслеживания особых ситуаций, когда в процессе поиска решения на одном из этапов пробная точка случайно совпадает с корнем. Однако прежде выполняется ряд инициализаций. Так, локальная переменная х определяется как левая часть равенства xint, указанного параметром процедуры. Переменным а и b присваиваются в качестве значений левая и правая границы диапазона, на котором ищется корень. А переменная f определяется как функциональная зависимость, соответствующая выражению, для которого ищутся корни.
и другие способы получения приближенных

Существуют и другие способы получения приближенных решений уравнения. Очень близок к методу половинного деления метод хорд или метод секущих. Принципиальное отличие от метода половинного деления состоит в том, что пробная точка теперь выбирается не в центре интервала, а является точкой пересечения координатной оси и секущей, проходящей через точки, определяемые значениями функции на границах интервала. По сравнению с методом половинного деления метод секущих обеспечивает более быструю сходимость итерационного процесса. К недостаткам метода можно отнести требование неизменности знака первой и второй производных в области поиска корня.
Если решаемое уравнение задается функцией f(x), а граничными точками интервала поиска являются их соответственно, то следующая пробная точка выбирается согласно соотношению. Поэтому процедура для вычисления корней уравнения методом секущих может быть получена из процедуры вычисления корней методом половинного деления, если заменить оператор присваивания значения переменной с и условие проверки точности. В качестве верхней границы для точности результата может быть выбран модуль отношения значения функции в точке предполагаемого решения (в процедуре — это f (с)) и минимального значения для производной этой функции на рассматриваемом интервале (параметр М). Вот код для этой процедуры.
предварительно оценив, что производная для
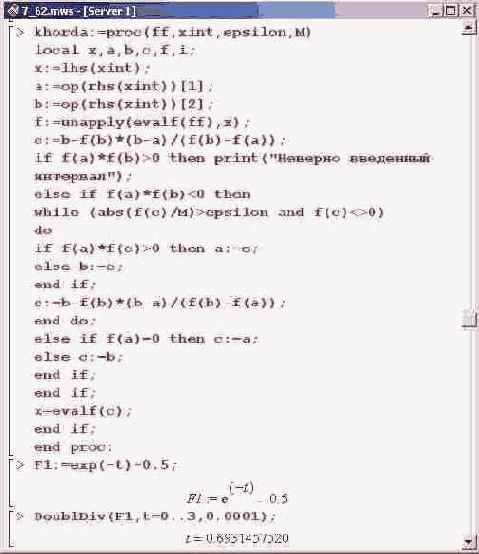
Теперь воспользуемся процедурой khorda(), предварительно оценив, что производная для Fl(x) по абсолютной величине меньше ехр(-З) на рассматриваемом интервале быть не может. Эту величину, преобразованную в формат числа с плавающей точкой, и указываем последним параметром процедуры khorda().
в пределах погрешности полностью совпадают.

Как видим, результаты в пределах погрешности полностью совпадают. Однако для процедуры khorda(), по сравнению с DoublDiv(), такое совпадение несколько хуже.
С учетом начального условия решим

С учетом начального условия решим данное уравнение в численном виде (решать уравнение в численном виде без начальных условий крайне проблематично).
Прежде чем появится результат, выводится

Прежде чем появится результат, выводится сообщение, гласящее буквально следующее: "Внимание, невозможно определить значение далее .96981062, возможна сингулярность". Поэтому значения функции будем определять только на интервале от 0 до указанного выше значения. Для того, чтобы вычислить значение функции в точке, следует указать эту точку аргументом определенной выше процедуры nsol(). Например, значение в нуле вычисляется так.
Решение задачи

Сами по себе эти значения

Сами по себе эти значения мало о чем говорят. Интересно их сравнить с точным решением уравнения. Maple с такой задачей справляется, однако результат довольно громоздок. Нас интересуют значения функции только в некоторых точках, причем значения эти, чтобы их можно было сравнивать, должны быть в формате чисел с плавающей точкой. Поэтому поступим следующим образом: решим уравнение, а к полученному результату применим операцию выделения функциональной зависимости unapply(). Результат присвоим переменной f, но выводить на экран его не будем.
Решение задачи

Как несложно заметить, совпадение данных

Как несложно заметить, совпадение данных более чем приемлемое.
Теперь попробуем "обойти" особенность, о которой шла речь в полученном выше предупреждении. Для этого в процедуре численного дифференцирования используем альтернативный метод вычислений. По сравнению с предыдущим случаем ниже будут внесены два существенных изменения. Во-первых, явно указано, что следует использовать классический метод (method=classical). Во-вторых, указано значение опции output, которое является массивом с явно выписанными точками, в которых будет вычисляться значение функции. Поэтому после выполнения соответствующей команды переменной nsol2 будет присвоена в качестве значения структура (матрица) с точками и значениями функции в этих точках.
в данном случае не появляются,

Никакие предупреждающие сообщения в данном случае не появляются, и значения для функции вычисляются для всего указанного диапазона. Однако точность оставляет желать лучшего.
Рассмотрим другое уравнение, уже второго порядка.
Поскольку выше значение опции output

Поскольку выше значение опции output указано равным listprocedure, в результате возвращается список равенств, левые части которых — переменная, функция и производная от этой функции, а правые части — процедуры, с помощью которых соответствующие значения могут быть вычислены. Предположим, что нас интересует значение производной функции в точке х. Тогда можем определить функциональный оператор dy.
после оператора присваивания первым параметром

Выше процедура eval () после оператора присваивания первым параметром содержит производную от функции у(х) по переменной х, а вторым параметром является определенная ранее процедура nums. В этом случае выражение (производная), указанное первым аргументом, вычисляется с использованием процедуры nums. Значения для производной на множестве точек можем получить следующим образом.
и значения самой функции. Проверим,

Аналогичным образом вычисляются и значения самой функции. Проверим, как численные методы работают при решении краевых задач. С этой целью определим следующее уравнение.
Будем вычислять значения функции на

Будем вычислять значения функции на интервале от 0 до 1 с шагом 0.1. Для этого вводим такую команду (метод решения краевой задачи вычислительным ядром определяется автоматически на основе классификации задачи).
Как всегда, сравниваем численное решение

Как всегда, сравниваем численное решение с точным. Определяем функциональный оператор, задающий точное решение задачи.
Совпадение хорошее. Однако следует проверить
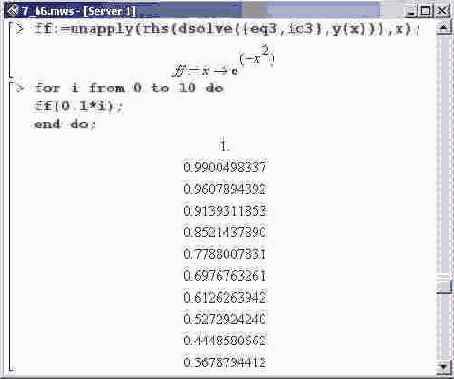
Совпадение хорошее. Однако следует проверить точность вычисления не только функции, но и ее производной.
Как видим, производная также вычисляется

Как видим, производная также вычисляется достаточно корректно.
Метод вычисления многократных интегралов на

Таблица 7.7. Значения опции method
| Значение | Описание |
| CCquad | Метод квадратур |
| _cuhre | Метод вычисления многократных интегралов на областях конечных размеров (новое в Maple 9 значение) |
| dOlajc | Адаптивный 10-точечный метод Гаусса с использованием правила Кронрода 21 точки. Применяется при конечных пределах интегрирования |
| _d01akc | Адаптивный 30-точечный метод Гаусса с использованием правила Кронрода 61 точки. Применяется при конечных пределах интегрирования с осциллирующими подынтегральными выражениями |
| _d01amc | Метод для вычисления интегралов на бесконечных интервалах |
| _DEFAULT | Эквивалент отсутствия явного указания метода интегрирования |
| _Dexp | Адаптивный метод двойного показателя |
| Gquad | Адаптивный метод квадратур Гаусса (новое в Maple 9 значение) |
| _NCrule | Метод Ньютона-Котеса |
| _NoNAG | Инструкция не использовать процедуры NAG |
| _NoMultiple | Инструкция не вызывать процедуры вычисления многократных интегралов. Такие интегралы вычисляются в этом случае через последовательное вычисление однократных интегралов (новое в Maple 9 значение) |
| MonteCarlo | Метод Монте-Карло. Используется для многократных интегралов. Это значение в версии Maple 9 заменило использовавшееся ранее значение dOlgbc |
| _Sinc | Адаптивный метод квадратур |
Далее рассмотрим интеграл от функции,

Далее рассмотрим интеграл от функции, имеющей особенность на границе интегрирования.
Явное указание метода интегрирования автоматически

Внимание!
Явное указание метода интегрирования автоматически означает, что никакие другие методы, в том числе и методы обработки сингулярностей, не используются.
Наконец, с помощью двойного интеграла вычислим площадь круга единичного радиуса.
воспользоваться приведенной выше командой

В Maple 9 воспользоваться приведенной выше командой не удастся из-за переопределения опции для метода Монте-Карло и изменения синтаксиса вызова команд вычисления многократных интегралов. В качестве утешения можно посчитать площадь квадрата.
Решение задачи

как работает созданная процедура. Для
Проверим, как работает созданная процедура. Для этого вызовем ее, указав в качестве базового интерполяционного списка созданный ранее генератором случайных чисел список В. Оценку для производной оставим в символьном виде. Кроме того, допускается использовать символьное выражение и для второго аргумента. Ниже приведен результат для точки х=2.5.
Встроенные процедуры Maple
Было бы удивительно, если разработчики Maple обошли стороной вопросы, связанные с проблемой интерполирования функций. В частности, для построения интерполяционного полинома в Maple предусмотрена процедура interp(). Процедура вызывается с тремя параметрами: списком значений узловых точек, списком значений интерполируемой функции в этих точках, а также названием переменной, которую следует использовать при построении интерполяционного полинома. Например, построим полином по значениям, приведенным в табл. 7.1.
В соответствии со значениями, приведенными в таблице, создаем два списка: сначала список X с узловыми точками, а затем список Y со значениями функции в этих точках.
Заключительные замечания
Описанные в этой главе приемы имели своей целью, в первую очередь, продемонстрировать возможности системы Maple в области численных расчетов. В этом отношении Maple не уступает ни одному из известных пакетов. Более того, возможности его, как правило, намного шире.
Представленные в главе материалы ни в коей мере не претендуют на полноту изложения и содержат краткий обзор доступных утилит. Следует также иметь в виду, что с новыми версиями Maple появляются новые пакеты, позволяющие решать самые различные задачи. Однако если читатель смог проникнуться идеей, заложенной создателями Maple в свой уникальный проект, он, без сомнения, легко освоит новые подходы.
