Основные устройства компьютера, его архитектура
Рассмотрим более детально, из каких устройств состоит компьютер и как эти устройства взаимодействуют друг с другом. Для нашего рассмотрения наиболее интересен вопрос устройства миникомпьютеров: персональных компьютеров, серверов, рабочих станций, ноутбуков. Современные компьютеры конструируются на основе идеологии открытых систем. Согласно этой идеологии отдельные устройства, составляющие компьютер, достаточно независимы друг от друга, могут иметь различную конструкцию и выпускаться различными фирмами. Однако они должны удовлетворять строгим предписаниям, касающимся взаимодействия друг сдругом. Эти предписания относятся как к техническим характеристикам устройств (например, величина напряжения на выходных контактах, форма и количество контактов в разъеме), так и содержания сигналов, которыми обмениваются устройства компьютера. Те компоненты устройства, назначением которых является взаимодействие с другими устройствами, называются его интерфейсом, а те правила, которым интерфейс обязан удовлетворять, называются протоколами.
Для устройств одинакового предназначения может существовать несколько протоколов. В этом случае можно объединять в одно целое только те устройства, которые работают по одинаковым протоколам. Например, очевидно, что в корпус компьютера можно вставить только те детали, которые подходят по размерам к специальным креплениям. Менее очевидны протоколы, относящиеся к синтаксису построения сигналов, которыми обмениваются устройства между собой. Большинство современных устройств могут работать с несколькими информационными протоколами.
Между собой все устройства компьютера соединяются шинами. (Более точно говорить о каналах связи, так как существуют и беспроводные соединения). В миникомпьютерах обычно все внешние устройства подсоединены к единому каналу связи, который называется общей шиной. Если ограничиться персональным компьютером, то в его состав могут входить устройства ручного ввода – клавиатура и мышь, устройство графического ввода – сканер, устройства вывода – монитор, принтер, графопостроитель (плоттер), внешние накопители информации – жесткий диск (винчестер), дисковод для гибкого диска (флоппи-диска), CD-ROM, звуковые колонки, сетевой выход.
1.5.1.Оперативная память.
1.5.2.Центральный процессор.
1.5.3.Системные шины.
1.5.4.Монитор.
1.5.5.Устройства ввода информации.
1.5.6.Внешние запоминающие устройства.
1.5.7.Устройства вывода информации.
1.5.8.Некоторые другие устройства.
Контрольные вопросы по теме.
Как связаны объем оперативной памяти и разрядность адресной шины?
Почему оперативная память электрическая, а не магнитная?
Можно ли вводить и выводить информацию без участия процессора?
Что такое видеопамять и чем она отличается от остальной оперативной памяти?
Зачем нужна постоянная память?
Зачем в компьютере нужен генератор тактовых импульсов?
Как управлять работой принтера?
В более мощных компьютерах используются специализированные внешние устройства.
Фактически устройства компьютера подключены к шине не непосредственно, а через промежуточные устройства, которые называются контроллерами или адаптерами. Использование контроллеров и адаптеров вызывается двумя обстоятельствами. Во-первых, характеристики сигналов в каналах связи отдельного устройства компьютера и в общей шине различны, и поэтому необходимо преобразование сигнала из одного вида в другой. Во-вторых, контроллер берет на себя некоторые стандартные операции процесса обмена информацией (такие, как опрос готовности устройства или контроль правильности передачи), освобождая от этих функций центральный процессор. Фактически контроллеры и адаптеры имеют свой процессор (который зачастую можно даже программировать) и представляют собой самостоятельный компьютер в миниатюре.
Выше уже было сказано, что весь комплекс средств, предназначенных для обеспечения связи конкретного устройства компьютера с другими устройствами, назывыается интерфейсом. Интерфейс включает в себя и соединительные каналы, и контроллеры или адаптеры, и алгоритмы, обеспечивающие управление устройством. От характеристик интерфейса зависит быстродействие и надежность устройства. Интерфейс стандартизирован согласно протоколам, описывающим устройства такого функционального предназначения. Стандартизация касается как технических параметров устройства, так и команд управления устройством. Схемы управления обычно помещаются внутри устройства.
Тип интерфейса, в котором общая шина используется всеми устройствами, подключенными к ней, на основе разделения времени, называется односвязным. При многосвязном интерфейсе одно устройство связывается с другими устройствами по нескольким независимым магистралям. Многосвязный интерфейс характеризуется тем, что каждое устройство снабжается одной выходной магистралью для выдачи информации и несколькими входными для приема информации от других устройств. Многосвязный интерфейс используется в больших и супербольших компьютерах.
При неисправности какой - либо входной шины или сопряженных с ней согласующих устройств, оказывается отключенным только одно периферийное устройство. Интерфейс автоматически определяет неисправное ПУ и выбирает исправные и незанятые магистрали. Процессор в зависимости от заданной программы выбирает последовательность опроса датчиков, т.е. вырабатывает управляющие сигналы обмена информацией по выбранному каналу и осуществляет сбор и обработку данных.
По цифровому каналу связи сигнал может передаваться параллельно или последовательно. Параллельная передача цифрового сигнала требует отдельные линии для каждого разряда, но является более быстродействующей. При последовательной передаче цифровые сигналы передаются последовательно по одной линии связи. По способу передачи информации во времени интерфейс может быть синхронный и асинхронный. Синхронный интерфейс характерен временной привязкой к тактовым сигналам, а асинхронный не требует постоянной временной привязки. При синхронной передаче данных тактовые сигналы процессора задают временной интервал, в течение которого считывается информация с одного датчика. Временной интервал определяется наибольшим временем задержки в системе передачи данных и максимальным временем преобразования сигнала. Асинхронная передача данных характеризуется наличием управляющих сигналов "Готовность к обмену", вырабатываемым внешним устройством, "Начало обмена", "Конец обмена", "Контроль обмена", вырабатываемых процессором. При такой организации обмена автоматически устанавливается рациональное соотношение между скоростью передачи данных и величинами задержки сигналов в канале связи.
Всей работой компьютера управляет процессор. Выражается это в том, что только процессор может посылать сигналы по шине адреса и шине управления. Все прочие устройства могут только считывать информацию, идущую по этим шинам. При одновременном прохождении сигнала по адресной шине и шине управления то устройство или тот байт памяти, адрес которого передается, «узнает этот адрес» и активируется.Прочитав сигнал, который идет по шине управления, устройство решает, что ему следует предпринять – принять информацию, идущую по шине данных или, наоборот, послать информацию по шине данных.
Таким образом, вся работа компьютера фактически сводится к информационным потокам и операциям обработки информации в процессоре. Еще раз подчеркнем, что именно процессор определяет, когда, кому и какое сообщение должно быть передано. В свою очередь, процессор извлекает эту информацию из компьютерной программы и данных, используемых программой. И то, и другое лежит в оперативной памяти. Даже если первоначально эти данные лежат на внешнем носителе, прежде чем они могут быть использованы компьютером (процессором!), они должны быть переписаны в оперативную память.
Поиск информации с применением серверов глобального поиска и каталогов
Пожалуй, самой полезной чертой Интернет является наличие в нем поисковых серверов. Это выделенные компьютеры, которые автоматически просматривают все ресурсы Интернет, которые могут найти, и индексируют их содержание. Затем Вы можете передать такому серверу фразу или набор ключевых слов, описывающих интересующую Вас тему, и сервер возвратит Вам список ресурсов, соответствующих Вашему запросу. Сегодняшние поисковые системы поддерживают индексы, включающие весьма значительную часть ресурсов Интернет. Таких серверов существует довольно-таки много, более десятка, и вкупе они охватывают практически все доступные ресурсы. К самым популярным русскоязычным поисковым серверам можно отнести rambler.ru, yandex.ru, yahoo.ru и другие.
В каталогах Интернет хранятся тематически систематизированные коллекции ссылок на различные сетевые ресурсы, в первую очередь на документы World Wide Web. Ссылки в такие каталоги заносятся не автоматически, но их администраторами. Более того, занимающиеся этим люди стараются сделать свои коллекции наиболее полными, включающими все доступные ресурсы на каждую тему. В результате пользователю не нужно самому собирать все ссылки по интересующему его вопросу, но достаточно найти этот вопрос в каталоге - работа по поиску и систематизации ссылок уже сделана за него.
Каталоги обычно имеют древовидную структуру и похожи на очень большой список закладок. Когда World Wide Web только начинала развиваться, и ее серверы еще можно было пересчитать, некоторые пользователи вели их списки. Со временем WWW-серверов становилось все больше, каждый день появлялись новые, и механизма закладок стало недостаточно для того, чтобы хранить эту информацию. Некоторые пользователи WWW стали создавать специальные программы для поддержания базы данных по ссылкам на ресурсы Интернет, ее автоматической синхронизации и управления ею. Именно так и родились глобальные каталоги сети, как, например, наиболее известный и крупный - YAHOO.
Как правило, хорошие каталоги Интернет обеспечивают разнообразный дополнительный сервис: поиск по ключевым словам в своей базе данных, списки последних поступлений, списки наиболее интересных из них, выдачу случайной ссылки, автоматическое оповещение по электронной почте о свежих поступлениях.
Все это делает использование таких коллекций весьма удобным.
Поисковые системы индексируют документы автоматически, не оценивая его завершенности или полезности. Поэтому они могут находить информацию в самых "глухих" углах Интернет. С другой стороны, если Вы неудачно сформулируете Ваш запрос, сервер может и не возвратить ссылки на нужный документ. В этом случае, если Вы определенно знаете, что из себя представляет искомый ресурс, и он наверняка хорошо известен, разумно обратиться к каталогам Интернет. Это решение также является адекватным в случае, когда Вам требуется наиболее полный список ресурсов по некоторому вопросу. Если же Вам нужна хотя бы одна ссылка, то использовать поисковый сервер гораздо быстрее.
Довольно-таки часто возникают ситуации, когда Вас интересует не информация о самом объекте, а ссылки на него в других, не связанных c ним непосредственно, документах. Тогда Вам тоже нужно воспользоваться поисковым сервером. То есть условно можно сказать, что каталоги - средство сфокусированного поиска информации, а поисковые серверы - рассеянного.
Каталоги и поисковые серверы - две стороны поиска информации в Интернет. Они разные по методам, но едины в целях. Научившись быстро использовать один, наиболее подходящий для Вас, каталог и несколько хороших поисковых серверов, Вы получите средство быстрого и эффективного нахождения информации в глобальной сети.
Понятие о программах и программировании
Программировать работу компьютера - это значит сделать так, чтобы компьтер совершил действие, которое вы для него предполагали. Программа - это полный набор инструкций, позволяющих компьютеру в каждой ситуации однозначно и правильно выполнить следующее действие. Весь процесс программирования в общем случае подразумевает формулировку цели программы, анализ содержания задачи с целью ее решения, создание программы в том виде, в котором она может быть воспринята компьютером, отладку программы и обеспечение функционирования программы в рабочем режиме.
В самой общей постановке программа должна преобразовывать набор входной информации в набор выходной информации. Для получения результата необходимо представить процесс вычисления в виде последовательности элементарных операций. Однако сам процесс написания программы далеко не прост. Формулировка желаемого результата некоторого действия редко включает описание самого действия. Очень часто получение нужного результата является очень сложной задачей, требующей оригинальных решений. Проблема здесь в том, что при обычном описании на естественном языке многие детали как очевидные остаются за кадром. Однако если мы формулируем формальное предписание, которое должно быть истолковано компьютером однозначно и не содержать неопределенности, мы должны предусмотреть все возможные варианты развития событий, все варианты возможных данных и правильно на них реагировать.
При этом существует много нюансов, связанных с тем, что при формулировке решения на естественном языке многие вещи опускаются за очевидностью. Между тем для того, чтобы компьютер мог их учесть, их надо формализовать. Процесс формулировки задачи таким образом, чтобы ее можно было описать числовой и текстовой информацией, а также составление самого описания называется математическим моделированием. Этап математического моделирования предшествует этапу непосредственного программирования. При этом многие авторы ставят на первое место не разработку алгоритмов, а разработку структурной организации информации, описывающей задачу. Такие авторы утверждают, что после удачного выбора структур данных построение алгоритмов работы с данными не представляет никаких трудностей. Конечно, как строгое правило это не верно, но в применении к большинству задач обработки информации, в-частности, для большинства экономических задач, мы склонны с ним согласиться.
чем анализировать принципы
Прежде, чем анализировать принципы и приемы соствления алгоритмов, приведем несколько примеров.
Пример 1. Вычисление расстояния между двумя точками на плоскости.

б).Программа на Паскале.
program length;
var x1,x2,y1,y2,r: real;
begin readln (x1,y1,x2,y2);
r := (x1-x2)*(x1-x2)+(y1-y2)*(y1-y2);
r := sqrt (r);
writeln (r)
end.
Пример 2. Вычислить частную сумму ряда

а). Блок-схема алгоритма с предусловием.
















 |
б). Блок-схема алгоритма с постусловием.















в). Программа на Паскале с предусловием и безусловным переходом.
program summa;
var k,n: integer; s: real;
label m1,m2;
begin readln (n);
s := 0; k := 1;
m1: if k>n then goto m2;
s := s + 1/(k*k); k := k+1; goto m1;
m2: writeln (s)
end.
г). Программа на Паскале с постусловием и безусловным переходом.
program summa;
var k,n: integer; s: real;
label m1;
begin readln (n);
s := 0;
k := 0;
m1: k := k+1;
s := s + 1/(k*k);
if k<=n then goto m1;
writeln (s)
end..
д). Программа на Паскале с оператором цикла с предусловием, эквивалентная программе пункта в).
program summa;
var k,n: integer; s: real;
begin readln (n);
s := 0;
k := 1;
while k<=n do
begin s := s + 1/(k*k);
k := k+1;
end;
writeln (s)
end.
е). Программа на Паскале с оператором цикла с постусловием, эквивалентная программе пункта г).
program summa;
var k,n: integer; s: real;
begin readln (n);
s := 0;
k := 0;
repeat k := k+1;
s := s + 1/(k*k);
until k>n;
writeln (s)
end.
ж). Программа на Паскале с оператором цикла со счетчиком.
program summa;
var k,n: integer; s: real;
begin readln (n);
for k := 1 to n do s := s + 1/(k*k);
writeln (s)
end.
З). Другой вариант цикла:
program summa;
var k,n: integer; s: real;
begin readln (n);
for k := n downto 1 do s := s + 1/(k*k);
writeln (s)
end.
Пример 3. Поиск значения x в массиве a.
а). Блок-схема алгоритма (длина массива равна 100).

















Элемент в массиве отсутствует
б). Фрагмент программы на Паскале.
var n,x: integer;
a: array [1..100] of integer;
label m1 ;
begin {Заполнить массив a}
readln (x);
for n:=1 to 100 do
if a[n] = x then goto m1;
n := 0;
m1: ...;
end.
Пример 4. Определение номера дня в невисокосном году по числу и месяцу (программа на Паскале).
function numerday (d,m: integer): integer; {d- день, m
- месяц}
const a: array [1..12] of
integer = (31,28,31,30,31,30,31,31,30,31,30,31);
b: array [1..12] of integer = (0,31,59,90,120,151,181,212,243,273,304,334);
begin if (m>=1) and
(m<=12) and (d>=1) and (d<=a[m] )
then numerday := b[m]+d
else numerday := 0
end;
Пример 5. Определение дня и месяца в невисокосном году по номеру дня.
а). Процедура на Паскале.
procedure date (n: integer; var d,m: integer);
const b: array [1..12] of
integer = (0,31,59,90,120,151,181,212,243,273,304,334);
var n: integer;
label m1;
begin for m:=1 to 11 do
if n<=b[m+1] then goto m1;
if n<=365
then m := 12
else m := 0;
m1: if m>0
then d := n - b[m]
else d := 0
end;
Пример 6. Установить, является ли данное целое число n простым.
а). Словесный алгоритм. Надо перебрать все натуральные числа k, меньшие квадратного корня из заданного числа n. Если для какого-то k число n делится на k нацело, то n составное, в противном случае оно простое.
б). Функция на Паскале.
function simple (n: integer): boolean;
var k,m: longint; b: boolean;
label m1;
begin b := true;
m := trunc (sqrt (n) );
for k:=2 to m do
if (n mod k)=0 then
begin b := false;
goto m1
end;
m1: simple := b
end;
Пример 7. Определить количество простых делителей в полном разложении заданного числа n.
а). Словесный алгоритм. Перебором в возрастающем порядке найдем наименьшее число k, на которое делится данное число n. Если k=n, значит число n простое и состоит из одного простого множителя. Если k<n, количество простых сомножителей числа n на единицу больше количества простых сомножителей числа n/k.
Это можно выразить так называемой рекуррентной формулой: f(n)=1+f(n/k). В этой формуле функция fn выражается через саму себя, но от меньшего значения аргумента.
б). Рекурсивная функция на Паскале (функция, в которой один из операторов представляет собой вызов себя самой).
function fn (n: longint): integer;
var k,m: longint; p: integer;
label m1;
begin p := 1;
m := trunc (sqrt (n) );
for k:=1 to m do
if (n mod k)=0 then
begin p := 1+fn (n div k);
goto m1
end;
m1: fn := p
end;
Пример 8. Описать событие: “Карта К1 бьет карту К2, включая учет козырной масти”.
а). Функция на Паскале.
type
suit = (spades, clubs, diamonds, hearts);
value = (c7,c8,c9,c10,jack,queen,king,ace);
card = record s: suit; v: value end;
function beat (sc: suit; c1,c2: card): boolean;
begin
if c1.s=sc
then beat := ( (c2.s <> sc) or ( (c2.s = sc) and (c1.v > c2.v) ) )
else beat := ( (c1.s=c2.s) and (c1.v > c2.v) )
end;
Пример 9. Определение количества простых чисел, меньших или равных данному числу n.
а). Алгоритм (решето Эратосфена).
Сначала все числа от 2 до n считаются простыми. Затем, начиная с 2, для каждого числа k, для которого уже установлено, что оно простое, производится следующая процедура: все числа, кратные k, считаются составными. Процедура заканчивается, когда k2>n. После этого подсчитывается число простых чисел.
б). Функция на Паскале.
function eratosphen (n: integer): integer; {n <= 255}
var
simple: set of 2..255; {Множество простых чисел}
k,m,p,s: integer;
begin
simple := [2..n]; {Сначала все числа от 2 до n считаются простыми}
m := trunc (sqrt (n) );
for k:=2 to m do
if (k in simple) then
begin
p := 2*k;
while p<=n do
begin
simple := simple - [p]; {Число p не является простым}
p := p+k
end
end;
s := 0;
for k:=2 to n do
if (k in simple) then s := s+1;
eratosphen := s
end;
Принципы работы операционной системы
Любая операционная система предполагает, что всеми ее действиями управляет основная программа операционной системы – ядро операционной системы. Ее также называют диспетчером операционной системы. Эта программа всегда хранится в специальной области внешнего носителя (на ПК – на винчестере). При включении компьютера начинают работать зашитые в ПЗУ программы начальной загрузки компьютера, которые после тестирования основных устройств компьютера считывают диспетчер в оперативную память и передают ему управление. С этого момента вплоть до выключения компьютера его работа определяется диспетчером. Механизм этого управления однотипен.
Диспетчер операционной системы получает команды из внешней среды. Это могут быть текстовые команды, набранные на клавиатуре (как в случае системы MS DOS), или щелчки мышью, как в Windows, или сообщения, полученные от работающих программ. В любом случае диспетчер анализирует команду (или сообщение), находит субъекта этой команды или сообщения (а именно: служебную программу операционной системы (утилиту) или какую-либо пользовательскую программу) и определяет характеристики команды, передающие особенности ее выполнения.
После этого диспетчер команд запускает соответствующую служебную программу ОС или пользовательскую программу, передав ей полученные характеристики в качестве параметров. Термин «запускает» означает следующее. Сначала диспетчер, пользуясь своими таблицами состояния вычислительной системы, определяет, загружена ли эта программа уже в оперативную память или еще нет. Если нет, то в оперативной памяти ищется незанятое место, выделяется участок необходимого размера и затем программа (или ее фрагмент) считывается из внешней памяти в данный участок ОЗУ. Для этого используются таблицы размещения файлов (и в том числе программ) на внешних носителях. При этом загруженная программа снабжается дополнительными программными блоками, которые должны обеспечить возвращение управления к диспетчеру операционной системы после временного или окончательного прекращения работы программы.
После этого управление передается на загруженную программу (с технической точки зрения для этого необходимо всего лишь занести в счетчик команд процессора адрес начала участка, где была размещена загруженная команда).
Подавляющее большинство действий операционная система выполняет по запросам работающих программ. Схема выполнения такого запроса следующая. В том месте программы, где ей необходимо выполнить, например, операцию ввода – вывода или выделения дополнительной оперативной памяти, ставится специальная команда, посылающая процессору так называемое программное прерывание. После этого процессор передает управление на блок обработки прерываний, который входит в состав диспетчера операционной системы, и последний в свою очередь, передает управление собственно диспетчеру. Диспетчер выполняет все вспомогательные действия (поиск или загрузка нужной утилиты, формирование параметров вызова, заполнение стека возврата), после чего передает управление утилите. Утилита выполняет нужные операции, после чего возвращает управление диспетчеру операционной системы. Диспетчер заканчивает операцию (при этом модифицируются таблицы описания текущего состояния вычислительного процесса и файловой системы) и передает управление основной программе, которая продолжает свою работу.
В операционной системе MS DOS диспетчером является программа с именем COMMAND.COM. На самом деле действие собствено диспетчера не слишком разнообразно и сама программа очень невелика. То же относится к диспетчеру системы Windows (программа с названием WIN.COM).
Проблемы Интернет
У Интернет есть, конечно же, свои трудности. Вот описание некоторых из них.
На известной юмористической картинке изображена собака, сидящая за компьютером, и говорящая другой: "В Интернете никто не знает, что ты - собака." Действительно, сегодня нет адекватных средств идентификации удаленных пользователей. Это, например, приводит к возникновению проблем с доступом к информации, открытой публично, но к которой "детям до 16 вход воспрещен". Проблема так называемого киберпорно сегодня бурно обсуждается и пока далека от решения.
Другой ряд проблем - сложность реализации законов об экспорте и авторских правах. Весьма проблематично ограничить доступ через Интернет к криптографическому программному обеспечению, запрещенному к вывозу из США и приравненному в этом плане к стратегическим вооружениям. Непонятно, что в Интернет защищается авторским правом, а что нет. Распространение электронной книги гораздо сложнее контролировать, нежели печатной, а значит и труднее продавать.
Интернет росла как свободная и малоуправляемая сеть. Соответственно, с ее ростом все сильнее встает проблема управляемости. Сеть коммерциализуется, все меньше и меньше несет исследовательскую информацию, но больше и больше рекламную. Сеть постепенно становится индустрией, и в первую очередь развлекательной. А это значит появление огромного нового рынка и коммерциализацию сети, что требует введения жестких правил игры. Все этопротиворечит сегодняшней коммунистической идеологии и свободе Интернет, а, значит, вызовет кардинальные изменения, которые вряд ли смогут пройти безболезненно.
Сегодня в Интернет используется протокол IP, использующий для адреса компьютера 32 бита. Однако, учитывая все ускоряющийся рост сети, адресное пространство может просто закончиться, причем это событие прогнозируется в пределах ближайших десяти лет. Для решения этой проблемы разрабатывается протокол IP нового поколения - IPng, в котором для адреса будет использоваться 128 бит, что позволяет адресовать астрономическое количество объектов.
Переход на новый протокол предполагается планомерно осуществить в оставшиеся до коллапса годы, но кто знает, сколь болезненным он окажется - ведь такие изменения требуют практически полной смены существующего программного обеспечения и активного сетевого оборудования.
Критическим вопросом для полноценного использования коммуникационных возможностей Интернет является вопрос безопасности данных. С одной стороны, компьютеры, подключенные к глобальной сети, становятся гораздо более уязвимыми. Но эта проблема в достаточной степени решаема, если точка взаимодействия корпоративной и глобальной сетей контролируема. С другой стороны, данные при прохождении от отправителя адресату могут быть прочитаны и даже изменены. Защита от опасностей такого рода весьма сложна, а средства ее обеспечения изощрены. Стопроцентных методов защиты сегодня просто не существует, но, как правило, принцип "стоимость вскрытия защиты должна быть выше ценности защищаемых данных" удается удовлетворить гораздо чаще
Процедуры и функции и оператор вызова процедуры (функции)
При составлении сложных программ почти всегда бывает необходимо разбивать всю задачу на несколько блоков и составлять алгоритмы для отдельных блоков задачи отдельно. Для выделенного блока формулируются требования к данным на входе и предполагаемый результат на выходе. Внутреннее устройство блока может варьироваться. Каждый блок в свою очередь может быть разбит на меньшие блоки и т.д. В результате вся сложная программа образует иерархическую структуру блоков, каждый из которых представляет собой самостоятельную, но более частную программу.
В Паскале подобная иерархическая структура формируется за счет механизма процедур и функций. Существует несколько веских причин для того, чтобы использовать механизм структурирования программы:
текст небольшой программы, содержание отдельных элементов которой описывается просто, хорошо читается и, как следствие, в нем делается меньше ошибок;
процедуры и функции можно отлаживать по отдельности, что позволяет производить поэтапную отладку программу и лучше локализовывать ошибки; достаточно сложные программы не могут быть отлажены другим способом;
для того, чтобы пользоваться процедурой, достаточно знать, как она действует, а не как она устроена, поэтому можно поручить программировать разные процедуры разным программистам; только так можно коллективно разрабатывать программы;
одна процедура, будучи написана, может использоваться в нескольких, иногда очень многих, программах; самые употребительные процедуры и функции встроены в Турбо-Паскаль и могут использоваться в любой программе;
механизм процедур и функций позволяет создавать программы с помощью наиболее современной технологии программирования “сверху-вниз”, при которой сначала пишется текст основной программы в форме вызовов вложенных процедур, а затем алгоритмизируются эти вложенные процедуры.
На каждую процедуру можно взглянуть двояко: извне и изнутри. При взгляде “изнутри” процедура представляет собой обычную программу, для которой к началу выполнения должны быть заданы входные значения, а к концу выполнения должны быть сформированы выходные значения.
При взгляде “извне” программист должен позаботиться только о том, чтобы передать процедуре те входные значения, которые она должна обработать, и получить от нее результат ее работы. Это достигается за счет использования параметров.
Каждая процедура или функция снабжается списком так называемых формальных параметров. Часть этих параметров объявляется выходными (входными в Паскале являются все). При взгляде “изнутри” все параметры являются обычными переменными с одним отличием: их значение известно к началу действия процедуры. После окончания действия процедуры некоторые параметры или все изменяют свое значение. При этом программист должен позаботиться о том, чтобы выходные параметры принимали нужные значения. При взгляде “извне” программист, если он хочет, чтобы процедура выполнилась, должен всего лишь указать значения параметров при входе в процедуру, а при выходе из нее получить значения тех параметров, которые объявлены выходными. Значения, присваиваемые формальным параметрам процедуры при обращении к ней, называются фактическими параметрами обращения к этой процедуре (или вызова процедуры).
В языке Паскаль взгляд “изнутри” реализуется в разделе описания процедур и функций. Этот раздел помещается после всех разделов объявлений программы, но до операторной части самой программы (то есть тела программы). В этом разделе описываются все процедуры и функции, используемые в программе. В Турбо?Паскале строение текста одной процедуры или функции в точности аналогично строению всей программы: заголовок, разделы объявлений, вложенные процедуры и функции и тело процедуры (функции). Вложенными называются такие процедуры и функции, текст которых помещен внутрь текста данной процедуры или функции. Надо отметить, что в стандартном Паскале вложение процедур и функций не допускается.
Разделы объявлений и тело процедуры идентичны соответствующим разделам программы. Заголовок процедуры состоит из ключевого слова procedure, имени процедуры и списка описаний формальных параметров в круглых скобках.
Список параметров может быть пустым, тогда он опускается:
procedure <имя процедуры> [( <список описаний формальных параметров> )]
Элементы списка отделяются друг от друга точкой с запятой. Описание формального параметра включает идентификатор формального параметра и указание его типа, разделенные двоеточием. Если параметр должен быть выходным, перед именем параметра ставится ключевое слово var. Указание типа в процедурах имеет одну особенность, отличающую его от указания типа при объявлении переменной: в качестве типа может использоваться только имя стандартного или пользовательского (определенного ранее в программе в разделе типов) типа, а не сложная конструкция вроде array ... of или record ... end. Если несколько идущих подряд параметров имеют одинаковый тип, то их описания можно объединить, поместив вместо одного имени параметра список имен, разделенных запятой. В общем случае формат описания формального параметра следующий:
[var] <список имен параметров через запятую> : <имя типа>
Для того, чтобы процедура фактически выполнилась, где-нибудь в программе или в другой процедуре должен стоять оператор вызова процедуры. Оператор вызова процедуры в общем случае применяется тогда, когда необходимо выполнить некоторое стандартное действие, встроенное в систему Турбо?Паскаль или предварительно оформленное в программе в виде процедуры или функции. Формат оператора вызова процедуры следующий:
<имя процедуры или функции> ( <список фактических параметров>)
Фактические параметры в списке разделены запятыми. Каждый фактический параметр согласно положению в списке соответствует своему формальному параметру и должен быть значением того типа, который был задан при описании формального параметра. Если параметр был описан как выходной с помощью ключевого слова var, то фактический параметр в операторе вызова процедуры обязан выражаться только именем переменной программы, а не произвольным выражением. В таком случае переменная на месте выходного параметра программы к началу выполнения следующего после вызова процедуры оператора примет то значение, которое имел соответствующий формальный параметр процедуры к концу работы процедуры.
Пусть, например, в процедуре p параметр y
выходной, а действует она следующим тривиальным образом:
procedure p (x: integer; var
y: integer);
begin
x := 0;
y := 0
end;
и пусть где-то в программе встретился фрагмент
a := 1; b := 1; p(a,b);
Тогда после выполнения вызова процедуры p(a,b)
переменная a будет иметь старое значение 1, а переменная b будет иметь новое значение 0.
Функция отличается от процедуры только тем, что она дополнительно вычисляет некоторое значение, которое возвращает при вызове. В результате возможно использование функций в качестве составной части выражения (а процедуры нет). При вычислении выражения функция вызывается и возвращаемое функцией значение подставляется в выражение. Если функция вызывается через оператор вызова, то возвращаемое значение игнорируется. Помимо возвращаемого значения, функция может выдавать другие выходные данные так же, как это делает процедура (через выходные параметры).
Заголовок функции начинается ключевым словом function и востальном идентичен заголовку процедуры за одним исключением: после списка формальных параметров через двоеточие указывается тип возвращаемого значения (который должен быть простым!):
function
<имя функции>
[( <список параметров>)] : <тип значения функции>
Для того, чтобы обеспечить возврат значения, в Паскале используется следующий механизм: в число переменных автоматически (без объявления) добавляется переменная с именем и типом, совпадающим с именем и типом функции. В конце работы функции этой переменной должно быть присвоено нужное значение. Например, для функции возведения в квадрат
function sqr (x: real): real;
begin sqr := x*x
end;
после присваивания a:=sqr(3) переменная a примет значение 9.
Использование процедур и функций порождает некоторые проблемы в использовании переменных. Рассмотрим операторную часть некоторой процедуры. В ней используются переменные и параметры данной процедуры. Однако не только они. В Паскале полагается, что в операторной части процедуры можно без ограничений использовать переменные самой программы.
Более того, если процедура вложена в другую процедуру, то можно использовать переменные и параметры объемлющей процедуры, а если и та вложена - то объемлющей последнюю и т.д. Другими словами, процедуре доступны все переменные и параметры процедур, внутри которых расположен текст данной процедуры. Такие переменные называются внешними в отличие от внутренних переменных самой процедуры. Возможен случай, когда переменные разных процедур имеют одинаковое имя. Тогда при использовании имени будет подразумеваться переменная внутренней процедуры, которая как бы закрывает внешнюю переменную от использования в операторной части внутренней процедуры.
Все сказанное о процедурах относится также и к функциям. Изложенные правила называются правилами локализации имен и относятся не только к переменным. Все объявления в процедуре и функции распостраняются только на текст процедуры и функции, но зато на весь этот текст, включая все вложенные процедуры и функции. Это касается и имен процедур и функций, вложенных в данную. Во внешней процедуре (в частности, в программе) все эти имена недоступны. Например, если процедура G1 содержит процедуру G2, а та содержит процедуру G3, то можно вызвать G3 из операторной части процедуры G2, но нельзя вызвать G3 из операторной части процедуры G1.
Указанные соглашения о локализации имен определяют два способа передачи информации вызываемой процедуре: посредством параметров и посредством использования внешних переменных. При первом способе мы должны определить соответствующий формальный параметр процедуры, и при вызове процедуры передать нужное значение в качестве фактического параметра. При этом не требуется, чтобы вызываемая процедура была вложена в вызывающую. При втором способе в вызываемой процедуре непосредственно используется имя внешней переменной вызывающей процедуры, но при этом обязательно первая процедура должна быть вложена во вторую. Приведем пример.
procedure
p1;
var i,j: integer;
procedure p2 (k: integer);
var i: integer;
begin {procedure p2} ... i := 2; j := 2; k := 3; ... end; {procedure p2}
begin {procedure p1} ... i := 1; j := 1; p2 (i); ... end; {procedure p1}
В процедуре p2 доступны внутренняя переменная i, которая закрывает доступ к одноименной внешней переменной процедуры p1, внешняя переменная j и параметр k. Значение переменной i передается процедуре p2 через параметр, а j - через непосредственный доступ к внешней переменной. После возврата из процедуры p2 в процедуру p1
переменная i сохранит старое значение 1, в то время как переменная j после присваивания j:=2 в процедуре p2 будет иметь значение 2. Заметим, что если бы формальный параметр k был определен в заголовке процедуры p2 как выходной (с ключевым словом var), то после вызова p2(i) значение переменной i оказалось бы равным 3.
Оба способа передачи значений имеют свои достоинства и недостатки. При передаче значений посредством параметров производится фактическое копирование значений во внутренние переменные процедуры. При больших объемах передаваемых данных это приводит к потерям времени и памяти. Широкое использование внешних переменных усложняет текст и затрудняет его чтение. Истина лежит где-то посередине.
Процессор и оперативная память компьютера
Теперь от рассмотрения абстрактных проблем перейдем к рассмотрению конструктивных особенностей компьютера, не вдаваясь при этом глубоко в технические детали. Сейчас нас интересует принципиальная сторона вопроса. В компьютере хранение данных и их обработка пространственно разделены. Ранее было сказано,что устройство, предназначенное для хранения данных, называется памятью компьютера. Устройство, производящее различные вычисления и управляющее работой компьютера, называется центральным процессором (ЦП). Полное состояние компьютера определяется той информацией, которая хранится в памяти компьютера. Удобно делить память на три основных раздела: адресуемая память (которая и называется оперативной памятью), регистры процессора и ячейки ввода-вывода (последний раздел является условным, так как он просто отображает процессы обмена информации с внешней средой).
Оперативная память (или оперативное запоминающее устройство - ОЗУ) в качестве составной части содержит постоянную память (или постоянное запоминающее устройство - ПЗУ). Постоянная память обладает той особенностью, что в нее нельзя записывать информацию. Нули и единицы в устройствах оперативной памяти изображаются электрическими сигналами, и поэтому информация в оперативной памяти бесследно исчезает при выключении питания. Однако постоянная память основана на других принципах хранения информации: в ней нули и единицы кодируются электрическими соединениями. При включении питания эту информацию можно прочитать.
Те условные ячейки, через которые информация может перемещаться из внешней среды в оперативную память и обратно, называются портами ввода-вывода. Для описания работы компьютера на принципиальном уровне можно считать, что в порты ввода из внешней среды (независимо или по запросу процессора) помещаются некоторые данные. Наоборот, при необходимости переслать данные куда-либо или сохранить их во внешней памяти нужно просто поместить эти данные в определенный порт вывода. Обо всем остальном позаботятся вспомогательные устройства компьютера.
О некоторых из них пойдет речь ниже.
В некоторые порты информация передается порциями по одному биту. Такой порт называется последовательным. Порт, в который информация передается порциями по одному или более байт, называется параллельным. Например, модем подключается к последовательному порту, а принтер – к параллельному.
Процессор – это центральное устройство компьютера. На него возложены две основные функции: во-первых, производить определенные вычисления, и, во-вторых, управлять работой всех узлов компьютера. Эти функции выполняют различные составляющие процессора: арифметико-логическое устройство (АЛУ) и устройство управления. Конструктивно процессор состоит из огромного количества электронных микросхем, сосредоточенных в микроскопическом объеме. Быть может, процессор является самым сложным устройством в мире. Весь прогресс в компьютерной индустрии связан с совершенствованием процессоров: расширением списка выполняемых ими функций, уменьшением объема и одновременным увеличением скорости выполнения операций (быстродействием), увеличением надежности. Именно для увеличения быстродействия данные перед непосредственным вычислением перемещаются из оперативной памяти в специальные ячейки, называемы регистрами процессора. Этих регистров несколько десятков и они выполняют различные функции.
Работа компьютера состоит из многих миллионов и даже миллиардов элементарных операций - машинных команд. Выполнение машинных команд предусмотрено в конструкции процессора. Для каждой команды в процессоре есть отвечающая за нее электронная микросхема. Все машинные команды делятся на группы в зависимости от класса выполняемой ими операции. Именно, команда выполняет действие одного из следующих типов:
¨ перемещает блок информации из оперативной памяти в регистры процессора;
¨ перемещает блок информации из регистров процессора в оперативную память компьютера;
¨ получает блок информации извне через один из портов и помещает ее в регистр процессора;
¨ выводит блок информации из регистра процессора через один из портов во внешнюю среду;
¨ инициирует операцию вычисления, выполняемую процессором: операция совершается над величинами, хранящимися в регистрах процессора, и результат помещается в другие или те же регистры;
¨ оповещает процессор о некоторой нештатной ситуации, называемой прерыванием: по этой команде процессор прекращает выполнение текущей программы и запускает другую программу, которая должна работать в случае прерывания данного типа.
Все содержательные операции совершаются непосредственно процессором над величинами, которые находятся в регистрах процессора. В частности, это арифметические и логические операции, а также операции преобразования. Эти операции фактически состоят из большого числа более мелких элементарных операций, каждая из которых производится над содержимым одного из разрядов одного из регистров. Многие из этих операций совершаются процессором параллельно (то есть одновременно). Для этого в компьютерах используется генератор тактовых импульсов, который синхронизирует работу различных частей компьютера. Каждая машинная команда состоит из определенного числа тактов. Один такт состоит из нескольких параллельно выполняемых операций. После выполнения всех тактов команды в одном из регистров процессора образуется правильный результат. Разные команды требуют различного количества тактов. В частности, число тактов при умножении чисел значительно больше, чем при сложении.
Перемещение информации между оперативной памятью и процессором и между оперативной памятью и портами происходит по системе соединений, которая называются шиной данных. Для увеличения скорости передачи биты информации передаются одновременно по нескольким линиям шины. Количество линий называется разрядностью шины. В персональных компьютерах используются 32-разрядные и 64-разрядные шины данных. По первой одновременно идет 4 байта информации, по второй – 8 байтов.
Однако для правильной организации работы компьютера процессор и память должны обмениваться не только данными, но и управляющими сигналами. Для этого в компьютере предусмотрены кроме шины данных еще две шины: шина адреса и шина управления (на самом деле есть еще шины питания, по которым на все устройства компьютера подается питание).
Шина адреса нужна для того, чтобы локализовать те ячейки оперативной памяти или те порты ввода-вывода, которые должны непосредственно участвовать в операции. Все байты оперативной памяти перенумерованы числами от нуля до максимального номера байта (последний зависит от объема оперативной памяти). Аналогично, перенумерованы также все порты ввода-вывода (обычно от 0 до 65535). Адресом байта в оперативной памяти считается его номер. Адресом участка памяти, состоящего из нескольких байтов (области памяти) служит адрес начального байта. Адресом порта ввода-вывода также служит его номер. При посылке предписания процессора к выполнению некоторой операции адрес того байта, который должен участвовать в операции, посылается процессором по шине адреса. При прохождении адреса по шине адреса активизируется именно тот байт памяти, номер которого совпадает с посланным адресом. Остальные управляющие сигналы, необходимые для правильного выполнения операции, посылаются по шине управления.
Для характеристики компьютера очень важна разрядность шины адреса. Например, у прежних персональных компьютеров использовалась 20-разрядная шина адреса. Максимальный адрес, который можно послать по такой шине, равен 220-1 = 1Мб, то есть байту оперативной памяти с адресом большим 1Мб предписание по шине адреса отправить невозможно. В таких компьютерах объем оперативной памяти принципиально не мог быть больше 1Мб. В процессорах этих компьютеров использовалась специальная система определения адреса, ориентированная на такое ограничение. В результате все программы, написанные в то время, предусматривали адреса до 1Мб.
Современные персональные компьютеры включают 32-разрядную шину адреса.
При такой шине максимальный объем оперативной памяти равен 232=4Гб. Пока этого достаточно, однако уже существуют компьютеры с 64-разрядной шиной адреса. При 32-разрядной шине можно обратиться к любому байту оперативной памяти в пределах 4Гб. Новые программы так и делают. Однако, к сожалению, необходимо предусмотреть возможность выполнения программ, написанных для старых процессоров. Поэтому в современных процессорах предусмотрены два режима работы: один режим, называемый реальным, имитирует работу старых процессоров, и в этом режиме осуществляется доступ только к 1Мг оперативной памяти; другой режим, называемый защищенным, имеет доступ ко всей оперативной памяти.
По шине управления идут сигналы, которые выполняют различные вспомогательные функции, необходимые для правильного выполнения операций. Всего линий в шине управления может быть более ста. Перечислим только некоторые линии управления. Существует линия переключения между оперативной памятью и портами ввода-вывода. Дело в том, что когда по шине адреса идет сигнал, то он может восприниматься и как номер байта оперативной памяти, и как номер порта ввода-вывода. Как именно воспринимать этот адрес, зависит от сигнала, который одновременно с адресом идет по управляющей линии (например, нуль на управляющей линии обозначает оперативную память, единица – порт). По другой управляющей линии идет сигнал, который задает направление перемещения информации (нуль – информация читается из памяти или из порта в регистр процессора, единица – пишется из регистра в память или порт). По третьей управляющей линии передаются сигналы от тактового генератора. Эти сигналы позволяют синхронизировать операции, которые должны одновременно выполняться сразу несколькими устройствами компьютера (например, подготовиться к очередной операции).
Все остальные устройства компьютера подключаются к одному из портов ввода-вывода. Очень часто одна и та же шина данных используется для обмена данными между процессором и всеми внешними входами и выходами.Такая шина называется общей шиной. Это означает, что в процессе работы компьютера процессор посылает сигналы, которые идут по общей шине и которые в принципе могут прочесть все подключенные к шине устройства. Однако реально они предназначаются только тому устройству, чей номер передается по шине адреса. Следует отметить, что эта простая однозвенная схема часто бывает усложнена. Реально устройства подключаются к общей шине не непосредственно. Некоторые порты могут быть подсоединены к одной из вспомогательных шин, которая в свою очередь прикрепляется к общей шине. Однако это не меняет принципиальной схемы работы компьютера.
Протокол PPP
Соединения типа "точка-точка" - протокол PPP (Point to Point Protocol). PPP - это более молодой протокол, нежели SLIP. Однако, назначение у него то же самое - управление передачей данных по выделенным или коммутируемым линиям связи. PPP обеспечивает стандартный метод взаимодействия двух узлов сети. Предполагается, что обеспечивается двунаправленная одновременная передача данных. Как и в SLIP, данные "нарезаются" на фрагменты, которые называются PPP-пакетами. Пакеты передаются от узла к узлу упорядоченно. В отличие от SLIP, PPP позволяет одновременно передавать по линии связи PPP-пакеты, содержащие внутри пакеты различных протоколов. Кроме того, PPP предполагает процесс автоконфигурации обоих взаимодействующих сторон. Собственно говоря, PPP состоит из трех частей: механизма инкапсуляции (encapsulation), протокола управления соединением (link control protocol) и семейства протоколов управления сетью (network control protocols).
В заголовке PPP-пакета, иногда называемого фреймом, в поле "протокол" указывается тип инкапсулированной содержательной части. Существуют специальные правила кодирования протоколов в этом поле. Далее в поле "информация" записывается собственно пакет данных, а в поле "хвост" добавляется "пустышка" для выравнивания на 32-битовую границу. По умолчанию для пакета PPP используется 1500 байтов. В это число не входит поле "протокол".
Протокол управления соединением предназначен для установки соглашения между узлами сети о параметрах инкапсуляции (размер фрейма, например). Кроме этого, протокол позволяет проводить идентификацию узлов. Первой фазой установки соединения является проверка готовности физического уровня передачи данных. При этом, такая проверка может осуществляться периодически, позволяя реализовать механизм автоматического восстановления физического соединения как это бывает при работе через модем по коммутируемой линии. Если физическое соединение установлено, то узлы начинают обмен пакетами протокола управления соединением, настраивая параметры сессии.
Любой пакет, отличный от пакета протокола управления соединением, не обрабатывается во время этого обмена. После установки параметров соединения возможен переход к идентификации. Идентификация не является обязательной. После всех этих действий происходит настройка параметров работы с протоколами межсетевого обмена (IP, IPX и т.п.). Для каждого из них используется свой протокол управления. Для завершения работы по протоколу PPP по сети передается пакет завершения работы протокола управления соединением.
Процедура конфигурации сетевых модулей операционной системы для работы по протоколу PPP более сложное занятие, чем аналогичная процедура для протокола SLIP. Однако, возможности PPP соединения гораздо более широкие. Так например, при работе через модем модуль PPP, обычно, сам восстанавливает соединение при потере несущей частоты. Кроме того, модуль PPP сам определяет параметры своих фреймов, в то время как при SLIP их надо подбирать вручную. Правда, если настраивать оба конца, то многие проблемы не возникают из-за того, что параметры соединения известны заранее. Более подробно с протоколом PPP можно познакомиться в RFC-1661 и RFC-1548.
Протокол SLIP
Протоколы SLIP (Serial Line Internet Protocol) или PPP (Point to Point Protocol) обеспечивают передачу пакетов TCP/IP по последовательным каналам, в частности, телефонным линиям, между двумя компьютерами. На обоих компьютерах работают программы, использующие протоколы TCP/IP. Индивидуальные пользователи получают возможность устанавливать прямое соединение с Internet со своего компьютера, имея модем и телефонную линию.
Технология TCP/IP позволяет организовать межсетевое взаимодействие, используя различные физические и канальные протоколы обмена данными. Однако, без обмена данными по телефонным линиям связи с использованием обычных модемов популярность Internet была бы значительно ниже. Большинство пользователей Сети используют свой домашний телефон в качестве окна в мир компьютерных сетей, подключая компьютер через модем к модемному пулу компании, предоставляющей IP-услуги или к своему рабочему компьютеру. Наиболее простым способом, обеспечивающим полный IP-сервис, является подключение через последовательный порт персонального компьютера по протоколу SLIP.
В отличии от Ethernet, SLIP не "заворачивает" IP-пакет в свою обертку, а "нарезает" его на "кусочки". При этом делает это довольно примитивно. SLIP-пакет начинается символом ESC (восьмеричное 333 или десятичное 219) и кончается символом END (восьмеричное 300 или десятичное 192). Если внутри пакета встречаются эти символы, то они заменяются двухбайтовыми последовательностями ESC-END (333 334) и ESC-ESC (333 335). Стандарт не определяет размер SLIP-пакета. SLIP-модуль не анализирует поток данных и не выделяет какую-либо информацию в этом потоке. Он просто "нарезает" ее на "кусочки", каждый из которых начинается символом ESC, а кончается символом END. Из приведенного выше описания понятно, что SLIP не позволяет выполнять какие-либо действия, связанные с адресами, т.к. в структуре пакета не предусмотрено поле адреса и его специальная обработка. Компьютеры, взаимодействующие по SLIP, обязаны знать свои IP-адреса заранее.
SLIP не позволяет различать пакеты по типу протокола, например. Вообще-то, при работе по SLIP предполагается использование только IP (что отражено в названии), но простота пакета может быть соблазнительной и для других протоколов. В SLIP нет информации, позволяющей корректировать ошибки линии связи. Коррекция ошибок возлагается на модули транспортного уровня - TCP, UDP.
SLIP/PPP действительно способ прямого соединения с Internet, поскольку:
¨ компьютер подсоединен к Internet;
¨ компьютер использует сетевое обеспечение для общения с другими компьютерами по протоколу TCP/IP;
¨ компьютер имеет уникальный IP-адрес.
Подключаясь посредством SLIP/PPP, можно запускать программы-клиенты WWW, электронной почты и т.п. непосредственно на своем компьютере. В чем же различие между SLIP/PPP-соединением и режимом удаленного терминала? Для установления как SLIP/PPP-соединения, так и режима удаленного терминала необходимо дозвониться к другому компьютеру, непосредственно соединенному с Internet (провайдеру) и зарегистрироваться на нем. Ключевое отличие состоит в том, что при SLIP/PPP-соединении Ваш компьютер получает уникальный IP-адрес и напрямую общается с другими компьютерами по протоколу TCP/IP. В режиме же удаленного терминала Ваш компьютер является всего лишь устройством отображения результатов работы программы, запущенной на компьютере провайдера.
В протоколе SLIP нет определения понятия "SLIP-сервер", но реальная жизнь вносит коррективы в стандарты. В контексте нашего изложения "SLIP-клиент" - это компьютер, инициирующий физическое соединение, а "SLIP-сервер" - это машина, постоянно включенная в IP-сеть.
Протокол TCP
Протокол TCP предоставляет транспортные услуги, отличающиеся от услуг UDP. Вместо ненадежной доставки датаграмм без установления соединений, он обеспечивает гарантированную доставку с установлением соединений в виде байтовых потоков. Протокол TCP используется в тех случаях, когда требуется надежная доставка сообщений. Он освобождает прикладные процессы от необходимости использовать таймауты и повторные передачи для обеспечения надежности. Наиболее типичными прикладными процессами, использующими TCP, являются FTP (File Transfer Protocol - протокол передачи файлов) и TELNET. Кроме того, TCP используют система X-Window, rcp (remote copy - удаленное копи-рование) и другие "r-команды". Большие возможности TCP даются не бесплатно. Реализация TCP требует большой производительности процессора и большой пропускной способности сети.
Внутренняя структура модуля TCP гораздо сложнее структуры модуля UDP. Прикладные процессы взаимодействуют с модулем TCP также через порты. Для отдельных приложений выделяются общеизвестные номера портов. Например,сервер TELNET использует порт номер 23. Клиент TELNET может получатьуслуги от сервера, если установит соединение с TCP-портом 23 на его машине. Когда прикладной процесс начинает использовать TCP, то модуль TCP на машине клиента и модуль TCP на машине сервера начинают общаться. Эти два оконечных модуля TCP поддерживают информацию о состоянии соединения, называемого виртуальным каналом. Этот виртуальный канал потребляет ресурсы обоих оконечных модулей TCP. Канал является дуплексным; данные могут одновременно передаваться в обоих направлениях. Один прикладной процесс пишет данные в TCP-порт, они проходят по сети, и другой прикладной процесс читает их из своего TCP-порта.
Протокол TCP разбивает поток байт на пакеты вне зависимости от его содержания и не сохраняет границ между записями. Например, если один прикладной процесс делает 5 записей в TCP-порт, то прикладной процесс на другом конце виртуального канала может выполнить 10 чтений для того, чтобы получить все данные.
Но этот же процесс может получить все данные сразу, сделав только одну операцию чтения. Не существует зависимости между числом и размером записываемых сообщений с одной стороны и числом и размером считываемых сообщений с другой стороны. Протокол TCP требует, чтобы все отправленные данные были подтверждены принявшей их стороной. Он использует таймауты и повторные передачи для обеспечения надежной доставки.
Отправителю разрешается передавать некоторое количество данных, не дожидаясь подтверждения приема ранее отправленных данных. Таким образом, между отправленными и подтвержденными данными существует окно уже отправленных, но еще не подтвержденных данных. Количество байт, которые можно передавать без подтверждения, называется размером окна. Как правило, размер окна устанавливается в стартовых файлах сетевого программного обеспечения.
Так как TCP-канал является дуплексным, то подтверждения для данных, идущих в одном направлении, могут передаваться вместе с данными, идущими в противоположном направлении. Приемники на обеих сторонах виртуального канала выполняют управление потоком передаваемых данных для того, чтобы не допускать переполнения буферов.
Почему существуют два транспортных протокола TCP и UDP, а не один из них? Дело в том, что они предоставляют разные услуги прикладным процессам. Большинство прикладных программ пользуются только одним из них. Вы, как программист, выбираете тот протокол, который наилучшим образом соответствует вашим потребностям. Если вам нужна надежная доставка, то лучшим может быть TCP. Если вам нужна доставка датаграмм, то лучше может быть UDP. Если вам нужна эффективная доставка по длинному и ненадежному каналу передачи данных, то лучше может подойти протокол TCP. Если нужна эффективность на быстрых сетях с короткими соединениями, то лучшим может быть протокол UDP.
Если ваши потребности не попадают ни в одну из этих категорий, то выбор транспортного протокола не ясен. Однако прикладные программы могут устранять недостатки выбранного протокола.Например,если вы выбрали UDP, а вам необходима надежность, то прикладная программа должна обеспечить надежность сама. Если вы выбрали TCP, а вам нужно передавать записи, то прикладная программа должна вставлять маркеры в поток байтов так, чтобы можно было различить записи.
Какие же прикладные программы доступны в сетях с TCP/IP? Общее их количество велико и продолжает постоянно увеличиваться. Некоторые приложения существуют с самого начала развития internet. Например, TELNET и FTP. Другие появились недавно: X-Window, SNMP. Протоколы прикладного уровня ориентированы на конкретные прикладные задачи. Они определяют как процедуры по организации взаимодействия определенного типа между прикладными процессами, так и форму представления информации при таком взаимодействии. Коротко опишем некоторые из прикладных протоколов.
Протокол UDP
Взаимодействие между прикладными процессами и модулем UDP осуществляется через UDP-порты. Порты нумеруются, начиная с нуля. Прикладной процесс, предоставляющий некоторые услуги другим прикладным процессам (сервер), ожидает поступления сообщений в порт, специально выделенный для этих услуг. Сообщения должны содержать запросы на предоставление услуг. Они отправляются процессами-клиентами. Например, сервер SNMP всегда ожидает поступлений сообщений в порт 161. Если клиент SNMP желает получить услугу, он посылает запрос в UDP-порт 161 на машину, где работает сервер. В каждом узле может быть только один сервер SNMP, так как существует только один UDP-порт 161. Данный номер порта является общеизвестным, то есть фиксированным номером, официально выделенным для услуг SNMP. Общеизвестные номера определяются стандартами Internet. Данные, отправляемые прикладным процессом через модуль UDP, достигают места назначения как единое целое. Например, если процесс-отправитель производит 5 записей в UDP-порт, то процесс-получатель должен будет сделать 5 чтений. Размер каждого записанного сообщения будет совпадать с размером каждого прочитанного. Протокол UDP сохраняет границы сообщений, определяемые прикладным процессом. Он никогда не объединяет несколько сообщений в одно и не делит одно сообщение на части.
Когда модуль UDP получает датаграмму от модуля IP, он проверяет контрольную сумму, содержащуюся в ее заголовке. Если контрольная сумма равна нулю, то это означает, что отправитель датаграммы ее не подсчитывал, и, следовательно, ее нужно игнорировать. Если два модуля UDP взаимодействуют только через одну сеть Ethernet, то от контрольного суммирования можно отказаться, так как средства Ethernet обеспечивают достаточную степень надежности обнаружения ошибок передачи. Это снижает накладные расходы, связанные с работой UDP. Однако рекомендуется всегда выполнять контрольное суммирование, так как возможно в какой-то момент изменения в таблице маршрутов приведут к тому, что датаграммы будут посылаться через менее надежную среду. Если контрольная сумма правильная (или равна нулю), то проверяется порт назначения, указанный в заголовке датаграммы. Если к этому порту подключен прикладной процесс, то прикладное сообщение, содержащееся в датаграмме, становится в очередь для прочтения. В остальных случаях датаграмма отбрасывается. Если датаграммы поступают быстрее, чем их успевает обрабатывать прикладной процесс, то при переполнении очереди сообщений поступающие датаграммы отбрасываются модулем UDP.
Пустой оператор
Пустой оператор - это пробелы, после которых стоит точка с запятой. Пустой опретор не вызывает никакого действия. Таким образом, лишняя точка с запятой в последовательности операторов не является ошибкой. Этого нельзя сказать об использовании точки с запятой внутри сложных конструкций (например, в условном операторе).
Раздел описания переменных
Раздел описания переменных озаглавливается ключевым словом var и включает список описаний переменных. Описания переменных отделяются друг от друга точкой с запятой. Каждое описание переменных состоит из одного или нескольких вводимых программистом имен переменной (несколько имен отделяются друг от друга запятыми), двоеточия “:“ и имени или расшифровки типа переменной:
<имя переменной> : <тип> ;
В разделе описания переменных должны быть упомянуты все переменные , используемые в программе. Тип, присвоенный переменной, ограничивает все значения, которые переменная может принимать в процессе выполнения программы. Присвоить сложный тип переменной можно двумя способами: либо записать его при объявлении переменной непосредственно, либо обозначить его именем в разделе типов, а при объявлении переменной указать только имя типа. Второй способ предпочтительнее тогда, когда одинаковый тип используется несколько раз. Второй способ обязателен, если вы хотите сделать совместимыми несколько переменных (в операторе присваивания) или переменные и параметры (при вызове процедуры, см. ниже). Примеры:
type
color = (white, black, red, blue, green, yellow, brown);
array1 = array [0..10] of integer;
record1 = record xx,yy: real;
nn: color
end;
set1 = set of colour;
var
x,y: real;
m,n,k: integer;
c1,c2: colour;
a1,a2: array1;
a3: array [0..10] of integer;
s1:set1;
s2: set of colour;
r1,r2,r3: record1;
Следует отметить, что в Паскале подход к определению типов строго бюрократический: хотя переменные a1 и a3 по сути одинаковые, формально они имеют разный тип и поэтому присваивание a1:=a3
незаконно (в то время как присваивание a1:=a1 правильное).
Раздел описания включаемых модулей
Раздел описания модулей озаглавливается ключевым словом uses и включает список имен включаемых в программу модулей (через запятую). Имя модуля является идентификатором , содержащим не более 8 символов. Модуль Турбо Паскаля - это библиотека готовых процедур и функций, необходимых для работы программы. Система Турбо?Паскаль содержит несколько стандартных модулей с именами Crt, Dos, Graph, Overlay, System, Printer. Кроме того, программист модет создать собственный модуль с тем, чтобы использовать его в нескольких разных программах. Файл, содержащий коды процедур и функций, входящих в модуль, имеет расширение *.TPU. Имя файла совпадает с именем модуля в разделе описания модулей. Пример описания модулей:
uses crt, dos, graph, user1;
В вышеприведенном примере транслятор подключит к вашей программе стандартные процедуры и функции модулей Crt, Dos, Graph и вашу библиотеку процедур и функций, хранящуюся в файле USER1.TPU.
Раздел определения констант
Раздел определения констант озаглавливается ключевым словом const и включает список определений констант. Описания констант отделяются друг от друга точкой с запятой. Каждое определение константы состоит из одного или нескольких вводимых программистом имен константы (несколько имен отделяются друг отдруга запятыми), знака равенства “=“ и значения константы:
<имя константы> = <значение контанты> ;
Если константа принадлежит составному типу или типу, введенному в разделе type, этот тип должен быть указан (такая константа называется типизированной):
<имя константы> : <тип> = <значение контанты> ;
Константа отличается от переменной тем, что значение ей присваивается при трансляции программы, а не в процессе выполнения, как для переменной. Обычно в раздел констант включают те данные, которые не меняются в процессе работы программы. Тип нетипизированной (без объявления типа) константы определяется автоматически по значению константы.
Значение нетипизированной константы может являться числом или символьной строкой или выражением, в которое могут входить также имена других констант. Подробнее об этом будет говориться тогда, когда будет разбираться использование выражений в операторе присваивания и других выражениях. Примеры нетипизированных констант:
const
const1 = 12;
const2, const3 = 3.14;
const4, const5 = true;
const6 = ‘A’;
c7 = 2*c2*c2;
Если тип типизированной константы комбинированный (массив или запись), то ее значение представляет собой совокупность нескольких элементарных значений. В этом случае после знака равенства помещается заключенный в круглые скобки список элементарных значений, разделенных запятой. Примеры:
type
color = (white, black, red, blue, green, yellow, brown);
rec1 = record
x: real;
c: color
end;
const
const8: array [2..5] of integer = (5, 22, 4, -3, 9);
const9: rec1 = (2.87, black);
Раздел определения меток
Раздел определения меток озаглавливается ключевым словом label и включает список имен меток (через запятую). Меткой может служить идентификатор или целое число без знака. Метки служат для фиксации определенного места в программе и используются в операторах безусловного перехода goto. Метка ставится перед помечаемым оператором и отделяется от него двоеточием “:”. Примеры:
label 11, m1, met2, 2, endoff;
Раздел определения типов
Раздел определения типов озаглавливается ключевым словом type и включает список определений типов. Каждое определение типов состоит из одного или нескольких вводимых программистом имен типа переменной (несколько имен отделяются друг отдруга запятыми), знака равенства “=“ и задания типа. Определение типа заканчивается точкой с запятой:
<имя типа> = <тип>;
Задание типа представляет собой запись, однозначно определяющую тип переменной. Это может быть имя стандартного типа (integer, real, char), имя типа, введенное программистом или одна из конструкций производного типа.
Концепция типа представляет собой, наверное, самый сложный элемент Паскаля. Язык Паскаль является строго типизированным языком. Это означает, что с каждым объектом программы связывается один определенный тип. Тип переменной задает множество возможных значений переменной и те операции, которые имеют смысл для значений данной переменной. Например, для целых и вещественных переменных имеют смысл арифметические операции и операции сравнения, для логических операций используются логические операции конъюнкции, дизъюнкции и отрицания и т.д. В результате некоторые ошибки, связанные с неправильным использованием переменной, могут быть выявлены непосредственно по тексту программы.
При компиляции информация о типе используется для определения объема памяти, которую необходимо выделить переменной, и для выбора команды выполнения операции: сложение целых чисел - это одна машинная команда, а сложение вещественных чисел - другая.
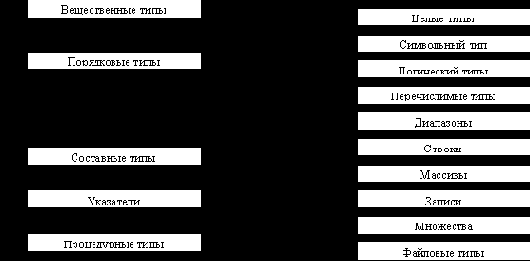
Числовых (и целых, и вещественных) типов в Турбо Паскале несколько. Связано это с тем обстоятельством, что в различных задачах числовые данные могут лежать в различных диапазонах, и для их представления необходим различный объем памяти.
Кроме того, иногда используются только положительные целые числа. В таблице перечислены стандартные простые типы системы Турбо Паскаль.
|
Ключевое слово |
Вид |
Диапазон |
Знач. цифры |
Длина (в байтах) |
|
byte |
целый без знака |
0..255 |
1 |
|
|
word |
целый без знака |
0..216-1 |
2 |
|
|
shortint |
целый со знаком |
-128..127 |
1 |
|
|
integer |
целый со знаком |
-215..215-1 |
2 |
|
|
longint |
целый со знаком |
-231..231-1 |
4 |
|
|
real |
вещественный |
2.9*10-39..1.7*1038 |
11-12 |
6 |
|
single |
вещественный |
1.5*10-45..3.4*1038 |
7-8 |
4 |
|
double |
вещественный |
5.0*10-324..1.7*10308 |
15-16 |
8 |
|
extended |
вещественный |
3.4*10-4932..1.1*104932 |
19-20 |
10 |
|
comp |
вещественный |
-263+1..263-1 |
19-20 |
8 |
|
char |
символьный |
ASCII |
1 |
|
|
boolean |
логический |
false, true |
1 |
type
color = (white, black, red, blue, green, yellow, brown);
m = (m1,m2,m3,m4,m5);
Идентификаторы, перечисленные в списке значений перечислимого типа, можно использовать в тексте программы, например, в операторе присваивания или в составе выражений. Кроме того, порядок написания значений перечислимого типа при его определении задает порядок в множестве значений, то есть законны операции сравнения значений перечислимого типа. Необходимо только, чтобы типы переменных при присваивании или сравнении были согласованными.
Отношение порядка, подобное отношению порядка значений перечислимого типа, называется линейным. Для него можно определить предыдущий и последующий элемент. Отношение порядка является линейным для всех простых типов, кроме вещественных. Конкретно:
для целого типа порядок определяется величиной числа;
для логического типа значение false предшествует значению true;
для символьного типа порядок определяется значением кода символа:
для перечислимого типа порядок задается порядком в списке значений при определении типа.
Все эти типы называются порядковыми. Значения порядковых типов можно сравнивать посредством операций “=“, “>“, “<“, “>=“, “<=“. Кроме того, для порядковых типов определены функции succ(x), pred(x) и ord(x), которые означают соответственно переход к следующему значению, переход к предыдущему значению и порядковый номер значения в множестве всех значений (начиная с нуля).
К числу составных типов относятся массивы, записи, множества и файлы. Каждый из этих типов описывается своей синтаксической конструкцией. Тип массива служит для описания переменной, состоящей из нескольких однотипных значений. Каждый элемент массива помечается целым числом или элементом другого порядкового типа, который называется индексом элемента. Массив задается указанием верхней и нижней границ индексов элемениов массива (диапазоном индексов) и типом элементов массива. Записывается это следующим образом:
array [<диапазон>] of <тип>
Диапазоном служат разделенные двумя точками (знак “..”) верхняя и нижняя границы массива. Память для массива выделяется в процессе компиляции программы, поэтому в качестве границ диапазонов могут выступать либо числа, либо константы, определенные в разделе констант, либо составленные из них выражения. Допускается вместо диапазона указывать имя перечислимого типа или такого стандартного типа, как boolean или char. Примеры:
array [0..100] of integer;
array [colour] of char;
array [char] of color;
В тексте программы элемент массива может являться как левой частью оператора присваивания, так и входить в состав выражения. В последнем случае элемент массива задается именем переменной, которой был присвоен тип массива, и значением индекса в квадратных скобках: <имя массива> [
<значение индекса> ]. Например:
var
b: integer;
a: array [1..5] of integer;
begin
a [1] := 1;
b := a [1] + 3;
end;
Возможны многомерные массивы (матрицы, таблицы), в которых задаются несколько диапазонов. Примеры:
var
a: array [1..4, 1..8] of real;
b: array [1..4] of array [1..8] of real;
c:
array [0..5, 2*3-1..10, 6..4*3] of boolean;
Первые два массивы идентичны. Обращаться к элементам указанных массивов можно одним из двух способов:
a [2,3] или a[2][3];
b [2,3] или
b[2][3];
c [0,7,11] или c[0][7][11].
Тип записи обозначает конгломерат разнотипных переменных. Отдельная переменная записи называется полем записи. Тип записи используется в случаях, когда описание объекта состоит из различных атрибутов, а программа должна иметь дело с несколькими объектами. Для задания записи указывается список определений полей. Определение поля записи отличается от стандартного определения типа тем, что вместо символа “=“ между идентификатором поля и указанием типа используется символ “:” (так, как это происходит при описании переменной, которое будет дано ниже). Определения типов в записи выделяются спереди и сзади ключевыми словами record
и end и отделяются друг от друга точкой с запятой. Примеры:
record
x,y: real;
m,n,k: integer;
a: array [1..12] of integer
end;
Тип множества соответствует переменной, значениями которой являются подмножества какого-либо базового множества. Реально в компьютере подмножество изображается строкой единиц и нулей, длина которой равна числу элементов базового множества. В Турбо Паскале число элементов множества не должно превосходить 256. Описание типа множества состоит из ключевых слов set of и задания базового множества. Множество задается либо указанием имени перечислимого типа, либо указанием диапазона целых чисел. Примеры:
type
color = (white, black, red, blue, green, yellow, brown);
set1 = set of color;
set2 = set of char;
set3 = set of 1..100;
Тип файла соответствует переменной, значением которой является файл.
Под файлом понимается объект Паскаля, которому соответствует реальный файл последовательного доступа во внешней памяти компьютера. Считается, что файл представляет собой упорядоченную последовательность элементов заданного типа. В некотором смысле он похож на объект, который мы назвали массивом. Разница заключается в том, что из программы мы можем обратиться к любому элементу массива (написав a[n]
), в то время как в файле в каждый момент времени имеется доступ только к одному элементу файла, называемому текущим. Для того, чтобы просмотреть или изменить элемент файла, следует сначала сделать его текущим. Другое отличие файла от массива заключается в том, что размер массива фиксирован, в то время как элементы к файлу можно добавлять произвольно.
Описание типа файла состоит из ключевых слов file of и указания типа файла. Примеры:
type
tfi = file of integer;
tfa = file of array [1..10]
of real;
typerec = record x,y: real;
m,n,k: integer;
a: array [1..12] of integer
end;
tfr = file of typerec ;
Рекурсия
В связи с рассмотрением деревьев уместно разобрать понятие рекурсии и его роль в прграммировании вообще и в Паскале в частности. Рекурсией называется использование при программировании процедуры в качестве оператора вызова этой же процедуры. Возможна опосредованная рекурсия, когда первая процедура вызывает вторую, а вторая процедура - первую. Основу для использования рекурсии составляют такие ситуации, когда подслучай общего случая подобен общему случаю и может быть проанализирован с помощью того же алгоритма, что и общий случай. Мы уже встречались с рекурсивным вызовом при решении задачи нахождении числа простых делителей натурального числа n. Аналогичная ситуация возникает в большинстве задач оперирования с деревьями индексов.
Особенность бинарных деревьев вообще и способа их описания с помощью указателей в частности заключается в том, что поддерево, образованное всеми потомками левого и правого сына корневой вершины, по своей структуре идентично самому дереву. Более того, для задания этого поддерева, как и для задания всего дерева, достаточно иметь указатель на корневую вершину поддерева. В этих условиях, например, задача перечисления всех вершин индексного инарного дерева в порядке возрастания решается следующей тривиальной рекурсивной процедурой (тип записи pterm определен в предыдущей главе):
procedure
write_list (pt: pterm); {Процедура вывода дерева (в файл или на печать}
begin
if pt^.left <> Nil then write_list (pt^.left); {Вывести левое поддерево}
write_term (pt^.num); {Вывести запись, соответствующую корню}
if pt^.right <> Nil then write_list (pt^.right) {Вывести правое поддерево}
end;
Также с помощью рекурсивных процедур можно реализовать алгоритм поиска записи в файле с помощью индексного дерева, который был приведен в предыдущей главе:
function find_rec (pt: pterm; v: type_val {тип записи поля упорядочения}): longint;
{Возвращает по указателю на корень и индексному значению номер записи или -1, если запись не найдена}
begin
if pt^.val=v then find_rec:=pt^.num; {Запись соответствует корню дерева}
else
if pt^.val>v then {Запись надо искать в левом поддереве}
if pt^.left = Nil {Левое поддерево отсутствует}
then find_rec := -1 {Запись не найдена}
else find_rec: = find_rec (pt^.left, v) {Запись ищется в левом поддереве}
elseif pt^.val<v then {Запись надо искать в правом поддереве}
if pt^.right = Nil {Правое поддерево отсутствует}
then find_rec := -1 {Запись не найдена}
else find_rec := find_rec (pt^.right, v) {Запись ищется в правом поддереве}
end;
При записи рекурсивных процедур на Паскале возникает одна маленькая проблема. В вышеприведенной программе компилятор узнает обращение к процедуре find_rec внутри процедуры find_rec, поскольку заголовок функции расположен ранее, чем вызов функции. Но если есть две функции, вызывающие друг друга, то один из вызовов обязательно будет раньше, чем заголовок соответствующей функции. Для того, чтобы разрешить это противоречие, в Турбо-Паскале разрешается записывать только заголовок функции или процедуры без тела процедуры. Такое предварительное объявление обозначается ключевым словом forward так, как это делается в следующем примере:
procedure p1(n: integer) forward;
procedure p2 (i,j: integer);
begin ... p1(4); ... end;
procedure p1;
begin ... p2(5,6); ... end;
Заметим, что во втором заголовке процедуры p1 нет необходимости указывать все реквизиты, поскольку они уже специфицированы в первом заголовке.
Другие примеры рекурсивных процедур и функций будут приведены в следующей главе.
Семейство протоколов TCP/IP
Термином TCP/IP называется целое семейство протоколов различного уровня. Сначала перечислим протоколы семейства.
¨ IP (Internet Protocol) – межсетевой протокол, давший название всему семейству;
¨ TCP (Transmission Control Protocol) - базовый транспортный протокол,
¨ UDP (User Datagram Protocol) - второй транспортный протокол, отличающийся от TCP;
¨ ARP (Address Resolution Protocol) - используется для определения соответствия IP-адресов и Ethernet-адресов;
¨ SLIP (Serial Line Internet Protocol) - протокол передачи данных по телефонным линиям;
¨ PPP (Point to Point Protocol) - протокол обмена данными "от точки к точке";
¨ FTP (File Transfer Protocol) - протокол обмена файлами;
¨ TELNET - протокол эмуляции виртуального терминала;
¨ RPC (Remote Process Control) - протокол управления удаленными процессами;
¨ TFTP (Trivial File Transfer Protocol) - тривиальный протокол передачи файлов;
¨ DNS (Domain Name System) - система доменных имен;
¨ RIP (Routing Information Protocol) - протокол маршрутизации;
¨ NFS (Network File System) - распределенная файловая система и система сетевой печати;
¨ SNMP (Simple Network ManagementProtocol) - простой протокол управления сетью.
К канальному уровню относятся стандарты SLIP и PPP. К сетевому (межсетевому) уровню относятся протоколы IP, ARP, ICMP. Транспортный уровень представлен протоколами TCP и UDP. Протоколы сервисов Интернет (FTP, TELNET, HTTP, GOPHER и т.п.) относятся к высшему, прикладному уровню.
В терминологии TCP/IP кадром называется блок данных, который принимается или отправляется сетевым адаптером. IP-пакетом называется блок данных, которым обменивается IP-модуль с сетевым интерфейсом. UDP-датаграмма – это блок данных, которым обменивается IP-модуль с UDP-модулем, TCP-сегмент – это блок данных, которым обменивается IP-модуль с TCP-модулем.
Наконец, прикладное сообщение – это блок данных, которым обмениваются программы сетевых приложений с протоколами транспортного уровня.
Инкапсуляциией называется способ упаковки сообщения в формате одного протокола в сообщение в формате другого протокола более низкого уровня (например, упаковка IP-пакета в кадр Ethernet или упаковка TCP-сегмента в IP-пакет). В рамках межсетевого обмена понятие инкапсуляции имеет расширенный смысл. Если в случае инкапсуляции IP-пакета речь идет действительно об упаковке IP-пакета внутри кадра Ethernet, то при передаче данных по коммутируемым каналам происходит дальнейшая разбиение пакетов на SLIP-пакеты или фреймы PPP.
Пусть прикладная программа сформировала сообщение, которое предназначено для отправки на другой компьютер. Это сообщение передается на вход одного из сетевых модулей. Сетевой модуль обрабатывает сообщение, если надо, разделяет его на пакеты, присоединяет заголовки и, в зависимости от результатов обработки, передает полученные пакеты тому или иному модулю. Следующий модуль проделывает аналогичную процедуру и т.д. Заканчивается процесс тогда, когда очередной пакет поступает на вход модуля сетевой системы (например, модуля ENET системы Ethernet).
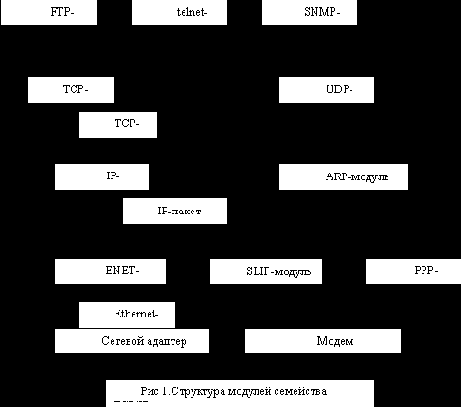
|
При работе с некоторыми программами прикладного уровня (такими, как FTP или telnet) используется модуль TCP. При работе с другими прикладными программами (NFS) используется модуль UDP. При получении сообщения от прикладной программы модули TCP и UDP работают как демультиплексоры, т.е. перенаправляют данные с нескольких выходов на один вход. Хотя технология Интернет поддерживает много различных сред передачи данных, здесь мы будем предполагать использование Ethernet, так как именно эта среда чаще всего служит физической основой для IP-сети.
Машина, принявшая пакет, осуществляет мультиплексирование в соответствии с этими отметками. Пусть сообщение пришло на сетевой интерфейс компьютера. Когда Ethernet-кадр попадает в драйвер сетевого интерфейса Ethernet, он может быть направлен либо в ARP-модуль, либо в IP-модуль. На то, куда должен быть направлен Ethernet-кадр, указывает значение поля типа в заголовке кадра. Если IP-пакет попадает в модуль IP, то содержащиеся в нем данные могут быть переданы либо модулю TCP, либо UDP, что определяется полем “протокол” в заголовке IP-пакета. Если UDP-датаграмма попадает в модуль UDP, то на основании значения поля “порт” в заголовке датаграммы определяется прикладная программа, которой должно быть передано прикладное сообщение. Если TCP-сообщение попадает в модуль TCP, то выбор прикладной программы, которой должно быть передано сообщение, осуществляется на основе значения поля “порт” в заголовке TCP-пакета.
Машина может быть подключена одновременно к нескольким средам передачи данных. Для машин с несколькими сетевыми интерфейсами при отправлении пакета IP-модуль выполняет функции мультиплексора, так как он должен сделать выбор между несколькими сетевыми интерфейсами.Таким образом, он осуществляет мультиплексирование входных и выходных данных в обоих направлениях. Данные могут поступать через любой сетевой интерфейс и быть переданы через любой другой сетевой интерфейс.
Процесс получения пакета и немедленной передачи его в другую сеть называется ретрансляцией IP-пакета. Ретранслируемый пакет не передается модулям TCP или UDP. Некоторые шлюзы вообще могут не иметь модулей TCP и UDP.
Сначала попробуем разобраться, как устроены протоколы передачи данных. Удобнее вначале рассмотреть, как работает сетевой модуль при приеме сообщения. Уже было сказано ранее, что для этого модуля сообщение представляет собой информативную начальную часть – заголовок, содержательную среднюю часть, которая была инкапсулирована в данное сообщение и для данного модуля представляет собой черный ящик, и, быть может, информативную конечную часть – хвост сообщения.
Работа модуля заключается в анализе заголовка и хвоста сообщения. Для этого прежде всего необходимо уметь выделять заголовок и хвост.
Тут может быть три способа. Либо все части сообщения имеют фиксированную заранее оговоренную длину, либо они будут выделены специальными маркерами, либо структура сообщения будет определяться в процессе анализа. Чаще всего используется последняя идея. Обычно протокол характеризуется набором полей, имеющих индивидуальную длину, измеряемую в байтах или битах. Однако заголовок конкретного сообщения не обязан включать все поля. Включение или невключение того или иного поля зависит от значения предшествующих полей заголовка. Протокол должен быть устроен таким образом, чтобы при последовательном просмотре сообщения для каждого текущего бита должно быть известно, к какому полю этот бит относится. Аналогично определяется начало содержательной части сообщения и хвост сообщения.
Проиллюстрируем сказанное на примере структуры IP-адреса, которая является частью протокола IP. Напомним, что IP-адрес узла идентифицирует сетевой адаптер, а не всю машину. IP-адрес имеет фиксированную длину, равную 4 байтам (32 битам). Старшие биты IP-адреса определяют номер IP-сети. Оставшаяся часть IP-адреса изображает внутренний номер узла в сети (хост-номер). Существуют 5 классов IP-адресов, отличающиеся количеством бит в сетевом номере и хост-номере. Класс адреса определяется значением старших битов первого байта . В таблице.1 приведены классы адресов и указано количество возможных IP-адресов каждого класса.
|
Класс |
1-й байт |
Значения первого байта |
2-й байт |
3-й байт |
4-й байт |
Возможное кол-во сетей |
Возможное кол-во узлов |
|
А |
0 + номер сети |
1 – 126 |
Узел |
126 |
16777214 |
||
|
B |
10 + начало номера сети |
128 – 191 |
Сеть |
Узел |
16382 |
65534 |
|
|
C |
110 + начало номера сети |
192 – 223 |
Сеть |
Узел |
2097150 |
254 |
|
|
D |
1110 + начало номера группы |
224 – 239 |
Группа |
- |
218 |
||
|
E |
11100 |
240 – 247 |
Зарезервировано |
Табл.1. Характеристики классов IP-адресов
Например, для машины с IP-адресом 221.137.10.34 сетевой номер равен 221.137.10, а хост- номер равен 34. Число 221 – это содержимое первого байта. Оно попадает в диапазон 192-223, поэтому данный IP-адрес относится к классу C. Числа 137 и 10 – соответственно содержимое второго и третьего байтов IP-адреса.
Адреса класса A предназначены для использования в больших сетях общего пользования. Они допускают большое количество номеров узлов. Адреса класса B используются в сетях среднего размера, например, сетях университетов и крупных компаний. Адреса класса C используются в сетях с небольшим числом компьютеров. Адреса класса D используются при обращениях к группам машин, а адреса класса E зарезервированы на будущее.
Прежде, чем вы начнете использовать сеть с TCP/IP, вы должны получить один или несколько официальных сетевых номеров. Выделением номеров (каки многими другими вопросами) занимается DDN Network Information Center (NIC). Выделение номеров производится бесплатно и занимает около недели. Вы можете получить сетевой номер вне зависимости от того, для чего предназначена ваша сеть. Даже если ваша сеть не имеет связи с объединенной сетью Internet, получение уникального номера желательно, так как в этом случае есть гарантия, что в будущем при включении в Internet или при подключении к сети другой организации не возникнет конфликта адресов. Одно из важнейших решений, которое необходимо принять при установк есети, заключается в выборе способа присвоения IP-адресов вашим машинам .Этот выбор должен учитывать перспективу роста сети. Иначе в дальнейшем вам придется менять адреса. Когда к сети подключено несколько сотен машин, изменение адресов становится почти невозможным. Организации, имеющие небольшие сети с числом узлов до 126, должны запрашивать сетевые номера класса C. Организации с большим числом машин могут получить несколько номеров класса C или номер класса B. Удобным средством структуризации сетей в рамках одной организации являются подсети.
Сервис telnet
Сервис telnet – это программа, обеспечивающая терминальный доступ к удаленным компьютерам. Она также используется как средство доступа к удаленным информационным сервисам, работа с которыми происходит в режиме текстового терминала. Telnet используется как часть информационного сервиса Интернет, когда при соединении пользователь попадает не в командный интерпретатор, но сразу в специализированную программу, обеспечивающую доступ к информационным ресурсам. Remote Login– удаленный доступ – это работа на удаленном компьютере в режиме, когда ваш компьютер эмулирует терминал удаленного компьютера, с которого можно делать все то же (или почти все), что можно делать с обычного терминала.
Сеанс telnet обеспечивается совместной работой программного обеспечения удаленного компьютера и Вашего. Они устанавливают TCP-связь и общаются через TCP и UDP пакеты.Так можно работать с каталогами некоторых библиотек.Можно получить доступ к терминальному навигатору WWW, если у Вас нет непосредственного доступа в Интернет. Серверов таких достаточно много, и они обслуживают самые разнообразные информационные сервисы.
Proxy («ближний») сервер предназначен для накопления информации, к которой часто обращаются пользователи, на локальной системе. При подключении к Internet с использованием proxy-сервера Ваши запросы первоначально направляются на эту локальную систему. Сервер извлекает требуемые ресурсы и предоставляет их Вам, одновременно сохраняя копию. При повторном обращении к тому же ресурсу предоставляется сохраненная копия. Таким образом, уменьшается количество удаленных соединений.
Использование proxy-сервера может несколько увеличить скорость доступа, если канал связи Вашего провайдера Internet недостаточно производителен. Если же канал связи достаточно мощный, скорость доступа может даже несколько снизиться, поскольку при извлечении ресурса вместо одного соединения от пользователя к удаленному компьютеру производится два: от пользователя к proxy-серверу и от proxy-сервера к удаленному компьютеру.
Сетевые новости Usenet
Сетевые новости Usenet, или телеконференции – еще один распространенный сервис Интернет. Usenet – это всемирный дискуссионный клуб. Если электронная почта передает сообщения по принципу "от одного - одному", то сетевые новости передают сообщения "от одного - многим". Механизм передачи каждого сообщения похож на передачу слухов: каждый узел сети, узнавший что-то новое (т.е. получивший новое сообщение), передает новость всем знакомым узлам, т.е. всем тем узлам, с кем он обменивается новостями. Таким образом, посланное Вами сообщение распространяется, многократно дублируясь, по сети, достигая за довольно короткие сроки всех участников телеконференций Usenet во всем мире. При этом в обсуждении интересующей Вас темы может участвовать множество людей, независимо от того, где они находятся физически, и Вы можете найти собеседников для обсуждения самых необычных тем.
Новости разделены по иерархически организованным тематическим группам, и имя каждой группы состоит из имен подуровней иерархии, разделенных точками, причем более общий уровень пишется первым. Рассмотрим, например, имя группы новостей comp.sys.sun.admin. Эта группа относится к иерархии верхнего уровня comp, предназначенной для обсуждения всего, связанного с компьютерами. В иерархии comp есть подуровень sys, предназначенный для обсуждения различных компьютерных систем. Далее, sun означает компьютерные системы фирмы Sun Microsystems, а admin обозначает группу, предназначенную для обсуждения вопросов администрирования таких компьютерных систем. Итак, группа comp.sys.sun.admin предназначена для обсуждения вопросов администрирования компьютерных систем фирмы Sun Microsystems. Набор групп, которые получает локальный сервер Usenet, определяется администратором этого сервера.
Всякий компьютер, подключенный к Интернет, имеет доступ к новостям Usenet, но новости Usenet распространяются и по другим сетям. В Интернет пользователь получает новости с сервера Usenet, и между просмотром списка сообщений, содержащихся в группе, и чтением этих сообщений нет задержки. Если Вы пользуетесь новостями через электронную почту, то Вы сначала получаете список статей, а уже потом принимаете по электронной почте статьи из списка, отдельно Вами заказанные.
Можно послать сообщение и просмотреть отклики на него, которые появятся в дальнейшем. Так как один и тот же материал читает множество людей, то отзывы начинают накапливаться. Все сообщения по одной тематике образуют поток или тему; таким образом, хотя отклики могли быть написаны в разное время и перемешаться с другими сообщениями, они все равно формируют целостное обсуждение. Вы можете подписаться на любую конференцию, просматривать заголовки сообщений в ней с помощью программы чтения новостей, сортировать сообщения по темам, чтобы было удобнее следить за обсуждением, добавлять свои сообщения с комментариями и задавать вопросы. Для прочтения и отправки сообщений используются программы чтения новостей.
Системное обеспечение работы в сети
Основное назначение сетевых операционных систем – обеспечение служебных функций обеспечения передачи данных канального и сетевого уровня. Сетевая система может как включать (как система Windows NT), так и не включать в свой состав обычную операционную систему отдельного компьютера (как система NetWare). В последнем случае для обычных операций (например, при работе с файлами) сетевая ОС пользуется соответствующими функциями обычной операционной системы.
Программное обеспечение сетевой операционной системы делится на две части. Одни модули располагаются на центральном сервере сети (если он есть) или на тех компьютерах, на которых лежат системные таблицы, управляющие сетью. Другие модули располагаются на каждой рабочей станции. Первые управляют работой сети. Вторые выполняют обычные протокольные функции – отправляют и получают пакеты, а также осуществляют посылку запросов к управляющим модулям.
Если это требуется, сетевая операционная система может по запросу одного компьютера запустить программу на другом компьютере. На этом основана распределенная обработка данных в сети. Вместо того, чтобы перекачать некоторый большой массив данных с центрального сервера на рабочую станцию с целью его обработки, с рабочей станции на сервер посылается запрос (или инструкция), задающий параметры обработки. Все вычисления выполняются на сервере (как правило, более быстродействующем, чем рабочие станции), а на рабочую станцию передаются только результаты обработки, имеющие значительно меньший объем. В резуьтате резко сокращаются объемы передаваемых данных, обеспечивается более гибкое управление доступом к данным. Внедрение объектно-ориентированных технологий позволяет упростить организацию построение систем распределенной обработки данных.
Задачей современных сетевых операционных систем становится объединение неравноценных операционных систем рабочих станций и обеспечение сетевого уровня для широкого круга задач: обработка баз данных, передача сообщений, управление распределенными ресурсами сети.
Существует несколько подходов к организации управления ресурсами сети.
При первом подходе системные таблицы находятся на каждом файловом сервере сети. Они содержат информацию о пользователях, группах, их правах доступа к ресурсам сети (данным, сервисным услугам и т.п.). Такая организация работы удобна, если в сети только один сервер. В этом случае требуется определить и контролировать только одну информационную базу. При расширении сети, добавлении новых серверов объем задач по управлению ресурсами сети резко возрастает. Администратор системы вынужден на каждом сервере сети определять и контролировать работу пользователей. Абоненты сети, в свою очередь, должны точно знать, где расположены те или иные ресурсы сети, а для получения доступа к этим ресурсам - регистрироваться на выбранном сервере. Конечно, для информационных систем, состоящих из большого количества серверов, такая организация работы не подходит.
Второй подход используется в LANServer и LANMahager - Структура Доменов (Domain). Все ресурсы сети и пользователи объединены в группы. Домен можно рассматривать как аналог таблиц объектов, только здесь такая таблица является общей для нескольких серверов, при этом ресурсы серверов являются общими для всего домена. Поэтому пользователю для того, чтобы получить доступ к сети, достаточно подключиться к домену (зарегистрироваться), после этого ему становятся доступны все ресурсы домена, ресурсы всех серверов и устройств, входящих в состав домена. Однако и с использованием этого подхода также возникают проблемы при построении информационной системы с большим количеством пользователей, серверов и, соответственно, доменов. Например, сети для предприятия или большой разветвленной организации. Здесь эти проблемы уже связаны с организацией взаимодействия и управления несколькими доменами, хотя по содержанию они такие же, как и в первом случае.
Третий подход - Служба Наименований Директорий или Каталогов (Directory Name Services - DNS) лишен этих недостатков.
Все ресурсы сети: сетевая печать, хранение данных, пользователи, серверы и т.п. рассматриваются как отдельные ветви или директории информационной системы. Таблицы, определяющие DNS, находятся на каждом сервере. Это, во-первых, повышает надежность и живучесть системы, а во-вторых, упрощает обращение пользователя к ресурсам сети. Зарегистрировавшись на одном сервере, пользователю становятся доступны все ресурсы сети. Управление такой системой также проще, чем при использовании доменов, так как здесь существует одна таблица, определяющая все ресурсы сети, в то время как при доменной организации необходимо определять ресурсы, пользователей, их права доступа для каждого домена отдельно.
Рассмотрим более подробно возможности некоторых сетевых операционных систем и требования, которые они предъявляют к программному и аппаратному обеспечению устройств сети.
NetWare, Novell. Отличительной чертой является эффективная файловая система широкий выбор аппаратного обеспечения. В качестве операционной системы используется собственная разработка Nowell. Для передачи данных используются протоколы IРХ/SРХ. Мультипроцессорность не предусматривается. Количество пользователей не должно превышать 250. Управление распределенными ресурсами сети осуществляется с помощью таблицы объектов на сервере. Защита от отказов в сети основана на дублировании дисков, зеркальном отражении дисков, резервном копировании таблиц и данных. В качестве файловой системы рабочих станций допускается DOS, Windows, Мас, ОS/2, UNIX, Windows NT.
LAN Server, IВМ Согр. Использует
доменную организации сети, что упрощает управление и доступ к ресурсам сети и обеспечивает полное взаимодействие с иерархическими системами (архитектурой SNА). LAN Server - целостная операционная система с широким набором услуг. Она работает на базе ОS/2, поэтому сервер может быть невыделенным. Обеспечивает взаимодействие с иерархическими системами, поддерживает межсетевое взаимодействие. Выпускаются две версии LAN Server: Entry и Advanced.
Версия Advanced в отличие от Entry поддерживает высокопроизводительную файловую систему (High Perfomance File System - HPFS). Она включает системы отказоустойчивости (Fail Tolerances) и секретности (Local Security).
Серверы и пользователи объединяются в домены. Серверы в домене работают как единая логическая система. Все ресурсы домена доступны пользователю после регистрации в домене. В одной кабельной системе могут работать несколько доменов. При использовании на рабочей станции OS/2 ресурсы этих станций доступны пользователям других рабочих станций, но только одному в данное время. Администратор может управлять работой сети только с рабочей станции, на которой установлена операционная система OS/2. LAN Server поддерживает удаленную загрузку рабочих станций DOS, OS/2 и Windows.
Система основана на операционной системе OS/2 2.х. В качестве коммуникационных протоколов используются протоколы: NetBIOS, ТСР/IР. Поддерживается мультипроцессорность. Максимальное количество пользователей - 1016. Система отказоустойчивости основана на дублировании дисков, зеркальном отражении дисков. Предусмотрена поддержка накопителя на магнитной ленте, резервное копирование таблиц домена. Клиент может использовать файловую систему DOS, Windows, Мас, OS/2, UNIX, Windows NT.
Windows NT, Microsoft Corp. Эта операционная система отличается простотой интерфейса пользователя и доступностью средств разработки прикладных программ и поддержка прогрессивных объектно-ориентированных технологий. Вследствие этого эта операционная система стала одной из самых популярных сетевых операционных систем.
Интерфейс напоминает оконный интерфейс Windows. Модульное построение системы упрощает внесение изменений и перенос на другие платформы. Обеспечивается защищенность подсистем от несанкционированного доступа и от их взаимного влияния (если зависает один процесс, это не влияет на работу остальных). Есть поддержка удаленных станций, но не поддерживается удаленная обработка заданий. Windows NT предъявляет более высокие требования к производительности компьютера по сравнению с NetWare.
Система основывается на протоколах NetBEUI, ТСР/IР, IРХ/SРХ, АррlеТаlk, АsyncBEUI. Поддерживается мультипроцессорность. Количество пользователей неограничено. Максимальный размер файла также неограничен. Для задания распределенных ресурсов используется система доменов. Защита от отказов включает дублирование дисков, зеркальное отражение дисков, RAID 5, поддержку накопителя на магнитной ленте, резервное копирование таблиц домена и данных. У клиента допускается файловая система DOS, Windows, Мас, ОS/2, UNIX, Windows NT.
NetWare 4, Nowell Inc. Эта система использует специализированную систему управления ресурсами сети, что позволяет строить эффективные информационные системы с количеством пользователей до 1000. В системе определены все ресурсы, услуги и пользователи сети. Эта информация распределена по всем серверам сети.
Встроенная поддержка Протокола Передачи Серии Пакетов позволяет передавать несколько пакетов без ожидания подтверждения о получении каждого пакета. Подтверждение передается после получения последнего пакета из серии. При передаче через шлюзы и маршрутизаторы обычно выполняется разбиение передаваемых данных на сегменты по 512 Байт, что уменьшает: скорость передачи данных примерно на 20%. Применение в NetWare 4 протокола LIP (Large Internet Packet) позволяет повысить эффективность обмена данными между сетями, так как в этом случае разбиение на сегменты по 512 Байт не требуется.
Все системные сообщения и интерфейс используют специальный модуль. Для перехода к другому языку достаточно поменять этот модуль или добавить новый. Возможно одновременное использование нескольких языков: один пользователь при работе с утилитами использует английский язык, а другой в это же время - немецкий.
Утилиты управления поддерживают DOS, Windows и OS/2-интерфейс. В качестве сетевого протокола используется IРХ/SРХ. Мультипроцессорность не поддерживается. Система защиты от отказов включает дублирование дисков, зеркальное отражение дисков, резервное копирование системных таблиц.Клиент может использовать файловые системы DOS, Windows, Мас(5), ОS/2, UNIX, Windows NT.
Системные шины
Системная шина представляет собой совокупность линий для передачи сигналов, объединённых по их назначению (данные, адреса, управление). Основной функцией системной шины является обмен информацией между процессором и остальными электронными компонентами компьютера. По системным шинам осуществляется передача информации (по шине данных), адресация устройств (по шине адреса) и обмен специальными служебными сигналами (по шине управления).
По шине данных происходит обмен информацией между процессором и оперативной памятью и между процессором и портами ввода-вывода. Важнейшей характеристикой шины данных является разрядность. В современных персональных компьютерах используется 64-разрядная шина данных (хотя эта информация очень быстро может устареть). По 64-разрядной шине одновременно можно передавать 8 байт данных.
По шине адреса процессор посылает адрес той ячейки памяти, которая должна участвовать в обмене. Если по одной из линий шины управления прошел сигнал о переключении на порт ввода-вывода, то адрес в адресной шине интерпретируется как номер порта. Разрядность адресной шины определяет максимально доступный номер байта оперативной памяти. В современных персональ
Шина управления состоит из линий, предназначенных для передачи различных управляющих сигналов. Кроме линии переключения между ОЗУ и портами ввода-вывода и линии переключения чтения-записи следует упомянуть линии аппаратных прерываний и линии требования внешними устройствами прямого доступа к памяти. Передачей информации по системной шине управляет одно из подключённых устройств или специально предназначенное для этого устройство, называемое арбитром шины.
Все современные персональные компьютеры располагают комбинированными системными шинами, такими как ISA (Industry Standart Architecture - стандартная промышленная архитектура), EISA (Extanded Industry Standart Architecture – расширенная стандартная промышленная архитектура) или PCI (Peripheral Component Interconnect – связь периферийных компонент).
Одна из шин называется первичной системной (EISA, ISA), а другая (PCI) вторичной системной.
Архитектура системной шины определяется типом процессора, применяемым набором микросхем и количеством и разрядностью периферийных устройств, подключаемых к шине. Так системные шины платформы Pentium (т.е. PCI) обеспечивают обмен центрального процессора с оперативной памятью 64-разрядами данных, при этом адресация данных осуществляется 32-разрядным адресом. С периферийными устройствами шина ISA поддерживает обмен 16-разрядным кодом данных и 16-разрядным адресным кодом данных, шина EISA - 32-разрядным кодом данных и 32-разрядным адресным кодом.
Часто используется в качестве критерия сравнения возможностей шин различной архитектуры максимальная пропускная способность шины. Её можно рассчитать, умножив её рабочую частоту на количество байт, передающихся в одном такте (ширину полосы пропускания). Например, системная шина PCI процессора Pentium имеет пропускную способность 533 Мбайт/с. Аналогично скорость обмена по шине ISA может достигать 16 Мбайт/с, по шине EISA - 33 Мбайт/с.
Если процессор имеет тактовую частоту выше частоты системной шины и/или способен исполнять несколько инструкций в одном такте, он может полностью использовать пропускную способность шины. Это приводит к задержкам, существенно снижающим производительность процессора. Увеличение пропускной способности требует увеличения либо тактовой частоты, либо разрядности шины данных.
Сортировка массивов и файлов
Сортировкой базы данных называется переписывание записей базы данных в порядке, задаваемом при сортировке. В случае, когда наряду с базой данных поддерживается индекс базы данных, сортировка данных сводится к записи в выходной файл записей исходной базы данных в порядке, заданном индексом (смотри выше). Если нужный индекс не поддерживается, то можно его создать и далее поступить аналогичным образом. Однако зачастую это нужно сделать быстро, а сортировка на основе индексирования не оптимальна по времени. Существуют много других методов сортировки. Мы приведем несколько алгоритмов для того, чтобы проиллюстрировать методы программирования вообще и задач информатики в частности.
Все изложение будет вестись на примере массивов, однако реальные алгоритмы сортировки для файлов устроены аналогично. Все, что надо для сортировки массива - это для любых двух записей уметь определять, которая из записей должна быть расположена раньше, а какая позже. Поэтому методы сортировки мы будем иллюстрировать на примере сортировки массивов целых чисел.
Пусть задан массив a целых чисел длины n. Первый способ сортировки называется сортировкой обменом. Идея алгоритма достаточно проста. Найдем среди элементов массива минимальный и поменяем его с первым элементом, затем найдем минимальный среди оставшихся и поменяем его со вторым элементом и т.д. Фрагмент программы на Паскале выглядит так:
for
j:=1 to n-1 do {Для всех элементов массива, кроме последнего, сделать}
begin m := j; {Ищем минимальный элемент (вначале j-й) }
for k:=j+1 to n do
if a[k]<a[m] then m:=k; {Текущий минимальный элемент - k-й}
x := a[j]; {Обменять минимальный элемент с j-ым}
a[j] := a[m];
a[m] := x
end;
Второй способ сортировки называется пузырьковым. В первом цикле, начиная с первого, сравниваются соседние элементы массива, и они переставляются, если последующий элемент меньше предыдущего.
В конце цикла самый большой элемент автоматически оказывается в конце массива (“всплывает” в конец массива, отсюда название “пузырьковый”). Во втором цикле то же самое проделывается с элементами массива, исключая последний, и т.д. Фрагмент программы на Паскале выглядит так:
for
j:=n downto 2 do {Для всех начальных частей массива сделать}
for
k:=1 to j-1 do {Сравнить все пары соседних элементов от первого до (j-1)-го}
if a[k]>a[k+1]
begin x := a[k]; {Обменять k-й элемент с (k+1)-ым}
a[k] := a[k+1];
a[k+1]:= x
end;
Третий способ сортировки называется сортировкой слиянием. Пусть массив a длины n и массив b
длины m уже отсортированы в возрастающем порядке, и пусть мы хоти молучить массив длины (n+m), состоящий из их объединения и также отсортированный. Это делается за один проход по массиву a и массиву b
следующим образом:
j:=1; k:=1; i:=1; {Текущими являются первые элементы массивов a, b и c}
while (j<=n) or (k<=m) do {Пока не кончатся оба массива}
begin
if (j<=n) and ((k>m) or
(a[j]<=b[k])) then
{Массив a не кончился, а массив b кончился, либо массив b не кончился и
текущий элемент массива a меньше или равен текущему элементу массива b}
begin c[i]:=a[j]; {Записываем в массив c элемент массива a}
j:=j+1; {Сдвигаем текущий элемент массива a}
l:=i+1 {Сдвигаем текущий элемент массива c}
end
else if (k<=m) and ((j>n) or
(a[j]>b[k])) then
{Массив b не кончился, а массив a кончился, либо массив a не кончился и
текущий элемент массива a больше текущего элемента массива b}
begin c[i]:=b[k]; {Записываем в массив c элемент массива b}
k:=k+1; {Сдвигаем текущий элемент массива b}
l:=i+1 {Сдвигаем текущий элемент массива a}
end
end;
Идея полного алгоритма сортировки массива слиянием заключается в следующем. Предположим для простоты, что длина массива равна степени двойки. Разобьем весь массив на пары соседних элементов и упорядочим каждку пару по возрастанию. Затем каждые две соседних пары сольем в одну упорядоченную четверку. В следующем цикле сольем каждые две соседних четверки в одну упорядоченную восьмерку и т.д. Для такого алгоритма необходима модификация описанной выше процедуры слияния, которая сливала бы два следующих друг за другом фрагмента одного массива и записывала результат в другой массив. Если длина массива не равна степени двойки, то сливаемые фрагменты массива могут иметь разную длину, но принципиально ничего не изменится.
Преимущество сортировки слиянием заключается в том, что один цикл слияния происходит за один проход всего массива и поэтому таким методом можно сливать не только массивы, но и большие файлы, списывая их фрагментами в массивы в оперативную память. Алгоритм при этом несколько усложняется, но принципиально остается тем же. Количество циклов при сортировке слиянием (число проходов по всему массиву или файлу) равно приблизительно log2n, где n - длина массива или файла.
Принципиально иной алгоритм сортировки основан на идее упорядочения массива по частям. Пусть m и M - минимальное и максимальное значения элементов массива. Положим b=(m+M)/2. Переставим элементы массива так, чтобы в начале шли ( в произвольном порядке) элементы, меньшие или равные b, а затем элементы большие b. Для этого будем двигаться одновременно с начала массива до элемента, большего b, и с конца массива до элемента, меньшего b. Как только мы их найдем, переставим эти элементы местами и начнем двигаться дальше. Процесс заканчивается тогда, когда мы встретимся где-то в середине массива. Соответствующий фрагмент программы на Паскале записывается так:
j:=1; k:=n; {Текущими являются первый и последний элементы массива}
while j<k do {Пока мы не встретимся в середине массива}
begin
while (j<k) and (a[j]<=b) do j:=j+1; { Дойти до номера j, для которого a[j]>b}
while (j<k) and (a[k]>b) do k:=k-1; {Дойти до номера k, для которого a[k]<=b}
if j<k then begin x := a[j]; {Поменять a[j] и a[k]}
a[j] :=a[k];
a[k]:=x
end
end;
После описанной процедуры осталось отсортировать отдельно первую часть массива (до конечного значения переменных j и k) и вторую часть массива. Для этого аналогичную процедуру нужно повторить для первой части массива и значения b1=(b+m)/2 и второй части массива и значения b2=(b+M)/2. Для полученных двух кусков первой и второй частей повторить то же самое и т.д. Процесс прекращается тогда, когда при делении образуются фрагменты массива длины 1. Конечно, процедуру нужно модифицировать таким образом, чтобы она умела разделять произвольные фрагменты массива с произвольным пороговым значением b.
Последний алгоритм, который мы здесь рассмотрим - это сортировка деревом. Предположим, что элементы массива размещены в вершинах бинарного дерева, то есть вершинами дерева будут номера элементов от 1
до n). Будем считать, что элемент a[k] подчиняет элементы a[2k] и a[2k+1] (если 2k+1 или 2k больше n, соответствующие стрелки в дереве отсутствуют). корнем дерева является элемент a[1]. Постараемся перестановками элементов добиться того, чтобы каждый отец был не меньше своих сыновей. Назовем такое дерево регулярным. Очевидно, максимальным в регулярном дереве является корень a[1]. Поменяем теперь элементы a[1]
и a[n] и будем рассматривать оставшуюся часть массива длины n-1. Эта часть не будет регулярным деревом, так как оно испорчено: одна из вершин (с номером n) выкинута, а ее значение перенесено в корень. Однако испорчено оно несильно и его можно быстро исправить: корень дерева нужно поменять местами с максимальным из его сыновей, этого сына - с максимальным из его сыновей и т.д., пока очередная вершина не окажется больше своих сыновей либо их не будет вовсе.
После этого в корне снова окажется максимальный элемент из оставшихся (n-1)-го, и его следует поменять с элементом a[n-1]. Производя подобную процедуру со все меньшими фрагментами массива, мы добьемся того, что массив будет весь отсортирован.
Приведем вспомогательную процедуру восстановления регулярности дерева в корне (k - длина еще не отсортированной части массива):
j :=
1; {дерево регулярно везде, кроме, возможно, вершины с номером j}
while ((2*j+1<= k) and
(a[2*j+1] > a[j])) or ((2*j <= k) and (a[2*j] > a[j])) do
if (2*j+1 <= k) and (a[2*j+1]>=a[2*j]) {Больше элемент a[2j+1]}
then begin x:=a[2*j+1]; {обменять местами a[j] и a[2j+1] }
a[2*j+1]:=a[j];
a[j] := x;
j := 2*j+1 {текущей будет вершина с номером 2j+1}
end
else begin x:=a[2*j]; {обменять местами a[j] и a[2j] }
a[2*j]:=a[j];
a[j] := x;
j := 2*j {текущей будет вершина с номером 2j}
end;
Возможно вместо указанного алгоритма использовать рекурсивную процедуру:
procedure
regul (j,k: integer); {Восстановить регулярность поддерева с корнем j в массиве длины k}
var i: integer;
begin
if 2*j> k then i:=0 {Вершина j не имеет подчиненных}
else
if 2*j= k then i:=2*j {Вершина j имеет одну подчиненную вершину 2j}
else {Вершина j имеет две подчиненные вершины 2j и 2j+1}
if a[2*j+1]>=a[2*j] {Выбрать максимальную из двух подчинееных вершин}
then i:=2*j+1
else i:= 2*j;
if (i>0) and (a[j]<a[i]) then {Вершина j не регулярная}
begin x := a[i]; {обменять местами a[j] и a[i] }
a[i] := a[j];
a[j] := x;
regul (i,k) {Рекурсивный вызов процедуры regul для того, чтобы восстановить
регулярность поддерева с корнем в вершине с номером i}
end
end;
Аналогичная процедура используется для того, чтобы сделать весь массив регулярным на начальной стадии сортировки. Мы не будем ее здесь приводить.
Составной оператор
Составной оператор используется тогда, когда по синтакису языка группу рператоров нужно считать одним оператором. Для этого последовательность операторов заключается в операторные скобки begin ... end :
begin
<оператор>;
. . . ;
<оператор>
end
Следует отметить, что после последнего оператора перед end точка с запятой не ставится. Однак если ее поставить, то это будет воспринято транслятором как наличие еще одного, пустого оператора и не приведет к ошибке.
Списки рассылки
Списки рассылки - простой сервис Интернет, работающий исключительно через электронную почту. Идея работы списка рассылки состоит в том, что существует некий адрес электронной почты, который на самом деле является общим адресом многих людей - подписчиков этого списка рассылки. Вы посылаете письмо на этот адрес, и Ваше сообщение получат все люди, подписанные на этот список рассылки.
Такой сервис по задачам, которые он призван решать, похож на сетевые новости Usenet, но имеет и существенные отличия. Во-первых, сообщения, распространяемые по электронной почте, всегда будут прочитаны подписчиком, дождавшись его в почтовом ящике, в то время как статьи в сетевых новостях стираются по прошествии определенного времени и становятся недоступны. Во-вторых, списки рассылки более управляемы и конфиденциальны: администратор списка полностью контролирует набор подписчиков и может следить за содержанием сообщений. Каждый список рассылки ведется какой-либо организацией и она обладает полным контролем над списком, в отличие от новостей Usenet, не принадлежащих никому и менее управляемых. В-третьих, для работы со списком рассылки достаточно доступа к электронной почте, и подписчиками могут быть люди, не имеющие доступа к новостям Usenet или каким-либо группам этих новостей. В-четвертых, такой способ передачи сообщений может быть просто быстрее, коль скоро сообщения передаются напрямую абонентам, а не по цепочке между серверами Usenet.
Ситуации, когда применяются списки рассылки как адекватное средство решения стоящих задач, достаточно характерны. Во-первых, организации часто создают списки рассылки для оповещения своих клиентов, пользователей своих продуктов или просто заинтересованных лиц о выпуске новых продуктов, коммерческих предложениях, различных новостях компании и т.д. Вторая ситуация, когда требуется заведение списка рассылки - когда обсуждается какой-то вопрос, слишком специфичный и интересующий слишком мало людей для того, чтобы заводить для него отдельную группу в новостях Usenet. В-третьих, списки рассылки часто заводятся виртуальными рабочими группами - людьми, работающими над одной проблемой, но живущими в различных точках планеты.
В зависимости от числа подписчиков, список рассылки обслуживается на сервере программами различной сложности, которые могут обеспечивать или не обеспечивать полную функциональность, а именно: автоматическую подписку клиентов и прием их отказа от подписки, проверку корректности электронных адресов, ведение архива сообщений, обработку почтовых ошибок, поддержку работы в режиме дайджеста (когда подписчик получает не каждое сообщение отдельным письмом, но периодически все сообщения за какой-то срок в одном письме), проверку сообщений администратором списка перед рассылкой и т.д.
Список задач для программирования на Паскале
Группа А.
1. Вычислить корни квадратного уравнения ax2+bx+c=0 (разобрать все значения a, b и c, указать число корней и корни).
2. Без использования массивов вычислить ln(1+x) с помощью ряда с точностью до 0.001.
3. Без использования массивов вычислить сумму ряда

4. Без использования массивов вычислить приближенное значение интеграла с помощью формулы

, где a, b
, n и f заданы, n - четное, h=(b-a)/n, a0=a, an=b, ak=a0+kh. Функция f(x)
вычисляется функцией на Паскале с заголовком function f(x:real): real; .
5. Без использования массивов найти минимальное по абсолютной величине число среди чисел sin1, sin2, ..., sinN (N£100) и определить, при каком N оно достигается.
6. Дан массив А из N элементов. Написать функции вычисления мах А
7. Дан массив А из N элементов. Написать функции вычисления sum A.
8. Подсчитать количество нулей в массиве a целых чисел.
9. Дан массив из N чисел. Найти в этом массиве номер 7-го по счету отрицательного элемента. Если число отрицательных элементов массива меньше 7, выдать 0. Построить функцию или фрагмент программы.
10. Генератор случайных чисел выдает числа от 0 до 99 (функция random (99) ). Выдать седьмое по счету четное число. Построить функцию или фрагмент программы.
11. Найти минимальное положительное значение в массиве a длины n.
12. Дано множестве n
точек на плоскости, заданных координатными парами (х,y). Найти две ближайшие.
13. Дан массив a
целых чисел, расположенных в возрастающем порядке (возможны повторения). За один проход по массиву найти количество различных чисел среди элементов этого массива.
14. Дан массив a
целых чисел, расположенных в возрастающем порядке (возможны повторения). Найти два соседних элемента с наибольшей разницей.
15. Написать функцию вычисления количества чисел в последовательности из n
элементов, которые меньше последующего члена.
16. Написать функцию вычисления максимума модуля разности между соседними членами последовательности из n элементов
17. Дан массив A целых чисел, расположенных в порядке убывания (возможны повторения). За один проход по массиву найти максимальное количество идущих подряд одинаковых чисел.
18. Пусть задан массив записей (объектов типа record), в число полей которой входит поле с именем old. Подсчитать количество элементов массива, для которых 18£old£55.
19. Используя только один цикл, определить, делится ли число n на число вида k2.
20. Найти наибольший общий делитель целых чисел m и n.
Группа Б
1. Найти максимальное из чисел, встречающихся в заданной последовательности более одного раза.
2. Найти максимальную по длине монотонную (неубывающую или невозрастающую) подпоследовательность в массиве a целых чисел.
3. Дан массив A длины n целых чисел, расположенных в возрастающем порядке (повторения невозможны). Для заданного числа x найти номер j элемента, для которого A[j]£x<A[j+1]. Если x<A[1], то j=0, если x³A[N] , то j=N.
4. Дан массив a произвольных целых чисел. Найти количество различных чисел среди элементов этого массива.
5. Двумя вызовами функции random (100) получаем координаты случайной точки (x,y), лежащей в квадрате со стороной 100. Сколько точек из N попадут внутрь круга с центром в точке (50, 50) и радиусом 25. Построить функцию или фрагмент программы.
6. Посчитать число счастливых четырехзначных билетов (сумма первых двух цифр равна сумме двух последних). Построить функцию или фрагмент программы.
7. Посчитать число чисел, меньших N, не делящихся на 7 и на 11. Построить функцию или фрагмент программы.
8. Не используя другого массива, заменить каждый элемент массива на среднее арифметическое своих соседей (первый и последний считаются соседями).
9. Дан массив a целых чисел. Не используя дополнительных массивов, переставить элементы массива в обратном порядке.
10. Пусть задан массив записей (объектов типа record), в число полей которой входит поле с именем name. Подсчитать количество элементов массива с данным значением x поля name.
11. Определить, является ли число n простым.
12. Год считается високосным, если он делится на четыре, при этом надо исключить года, делящиеся на 100 и не делящиеся на 400. Вычислить логическое выражение, принимающее значение true, если данный год является високосным.
13. Определить, делится ли число n на квадрат другого числа.
14. Пусть гостиница состоит из n корпусов с различным числом номеров, задаваемых массивом a . Нумерация номеров в гостинице сквозная. По номеру определить корпус, в котором находится этот номер.
15. Построить функцию, моделирующую дискретную случайную величину с заданным распределением p1, p2, ... ,pn.
16. Вычислить номер дня в невисокосном году по числу и месяцу.
17. Вычислить число и месяц в невисокосном году по номеру дня.
18. Определение номера дня недели по дате (день, месяц, год) с вводом данных и проверкой.
19. Определение месяца и числа по году и номеру дня в году с вводом данных и проверкой.
20. Сортировать массив a длины n в порядке возрастания обменом.
21. Сортировать массив a длины n в порядке возрастания пузырьком.
22. Коэффициенты многочлена a0+a1x+a2x2+...+anxn хранятся в массиве a длины n+1. Вычислить значение производной этого многочлена в точке x.
23. В массивах a
и b длины n+1 и k+1 хранятся коэффициенты двух многочленов степеней n и k. Поместить в массив c длины n+k+1 коэффициенты их произведения.
24. Дано множестве n
точек на плоскости, заданных координатами (х,y). Найти вторую по удаленности пару в списке всех пар точек данного множества.
25. По матрице a
размером 2n*2m построить матрицу b размером nxm, элементы которой есть суммы четырех элементов соответствующей ячейки 2*2.
26. Умножить две матрицы порядков m*n и n*k.
27. Транспонировать матрицу относительно главной диагонали.
28. Транспонировать матрицу относительно побочной диагонали.
29. Ряд Фибоначчи задается формулой a=1, a=2, a= a+a. Вывести на экран члены ряда от 1 до 35 в четыре столбика по 10 членов (последний неполный). Можно использовать дополнительный массив.
30. Число называется совершенным, если оно равно сумме своих делителей, включая 1. Например, 6=1+2+3. Найти все совершенные числа от 1 до n и вывести их на экран.
31. В строке определить правильность расстановки круглых скобок (соответствие открывающих и закрывающих).
32. Написать функцию преобразования целого числа в двоичную строку.
33. Написать функцию преобразования двоичной строки в целое число.
Группа В
1. Дан массив A целых чисел, расположенных в возрастающем порядке. Длина массива – 1024. Для заданного числа x не более чем за 20 сравнений найти номер j элемента, для которого A[j]£x<A[j+1].
2. Слить два упорядоченных по возрастанию массива a и b в массив c.
3. Не используя другого массива и не используя сортировки, переставить элементы массива a длины n так, чтобы вначале шли элементы меньше b, а затем элементы больше b (b
задано).
4. Заданную последовательность v длины n преобразовать таким образом, чтобы вначале шли неположительные, а затем положительные элементы. Не использовать других массивов и не сортировать массив.
5. Вывести на дисплей календарь января 1997г.
6. Дан массив a целых чисел. Не используя дополнительных массивов, переставить элементы массива так, чтобы вначале шли четные, а затем нечетные числа.
7. Дан массив целых чисел a длины m+n, рассматриваемый как соединение двух его отрезков: начала длины m и конца длины n. Не используя дополнительных массивов, переставить начало и конец.
8. Написать процедуру сортировки (любым способом) строк матрицы размером N*N в порядке убывания длины строки (строка рассматривется как вектор).
9. Дана матрица размером N*N. Определить, где положительных чисел больше - над главной диагональю (включая ее) или под ней (не включая главную диагональ). Построить функцию или фрагмент программы.
10. Определить, есть ли среди делителей числа n два, отличающихся на единицу.
11. Подсчитать количество делящихся на 11 чисел от 1 до n, в записи которых нет двоек и семерок.
12. Подсчитать сумму всех простых делителей данного числа n (кратные считать столько раз, какова их кратность).
13. Поместить в массив a все простые делители числа n в порядке возрастания (с учетом кратности).
14. Проверить правильность расстановки круглых и квадратных скобок в символьной строке. Указание: хранить дополнительную строку открытых к текущему моменту скобок.
Закрывающая скобка должна соответствовать типу последней открытой скобки.
15. Подсчитать количество слов в заданной строке. Разделителями считать пробел, точку, запятую и точку с запятой.
16. Написать функцию, удаляющую из строки все повторяющиеся, лидирующие и замыкающие пробелы.
17. Построение и вывод символьной строки, изображающей n-ричное представление целого числа, n£16.
18. Расставить на шахматной доске восемь ферзей , не бьющих друг друга.
19. Игра "Ханойские башни" состоит в следующем. Есть три стержня. На первый из них надета пирамидка из n колец (большие кольца снизу, меньшие сверху). Требуется переместить кольца на второй стержень. Разрешается перекладывать кольца со стержня на стержень, но класть большее кольцо поверх меньшего нельзя. Написать рекурсивную процедуру, осуществляющую следующую идею: чтобы переложить k верхних колец с 1-го стержня на 2-ой, надо переложить (k-1) кольцо с 1-го стержня на 3-ий, k-ое кольцо переложить на 2-ой стержень, а затем (k-1) колько переложить с 3-го стержня на 2-ой.
20. Построить рекурсивную процедуру, определяющую, содержит ли данное число нечетные простые делители, дающие при делении на 4 остаток 1.
Структура программы на Паскале
Программа на Паскале состоит из заголовка программы, описания данных, описания процедур и функций и описания действия программы. В свою очередь описание процедуры или функции такжк состоит из заголовка, описания данных и описания действия процедуры (функции). Заголовок программы содержит ключевое слово program, имя программы и список описаний параметров программы. Заголовок процедуры или функции отличается только ключевым словом (соответственно procedure
или function). Список описаний параметров программы заключен в круглые скобки. Различные описания списка отделяются друг от друга точкой с запятой.
Описание данных состоит из нескольких разделов. Каждый раздел предваряется своим ключевым словом. Типы разделов следующие:
раздел определения типов (ключевое слово type);
раздел описания переменных (ключевое слово var);
раздел определения констант (ключевое слово const);
раздел описания меток (ключевое слово label);
раздел описания включаемых модулей (ключевое слово uses).
Описание действия программы называется телом программы. Тело программы состоит из списка операторов, начинающихся ключевым словом begin и заканчивающихся ключевым словом end с точкой (т.е. end.). Для процедур и функций после end стоит точка с запятой. Операторы друг от друга отделяются точкой с запятой. Комментарии могут быть вставлены на любое место в программе на границе между словами.
Рассмотрим отдельные разделы программы подробнее.
Технологии функционирования локальной сети
Наиболее популярными технологиями, применяемыми при построении локальных сетей, являются технологии Ethernet, Token Ring и Arknet. Эти технологии относятся к канальному уровню обеспечения работы локальной сети. Соответственно в них используются разные канальные протоколы, основанные на разных алгоритмах обработки.
Локальная сеть Ethernet. Спецификацию Ethernet в конце семидесятых годов предложила компания Xerox Corporation. Позднее к этому проекту присоединились компании Digital Equipment Corporation (DEC) и Intel Corporation.
Метод Ethernet обеспечивает высокую скорость передачи данных и надёжность На логическом уровне в Ethernet применяется топология шина. Поэтому сообщение, отправляемое одной рабочей станцией, принимается одновременно всеми остальными станциями, подключёнными к общей шине. Но сообщение предназначено только для одной станции (оно включает в себя адрес станции назначения и адрес отправителя). Та станция, которой предназначено сообщение, принимает его, остальные игнорируют.
Метод доступа Ethernet является методом множественного доступа с прослушиванием несущей и разрешением коллизий (конфликтов) Перед началом передачи рабочая станция определяет, свободен канал или занят. Если канал свободен, станция начинает передачу. Ethernet не исключает возможности одновременной передачи сообщений двумя или несколькими станциями. Аппаратура автоматически распознаёт такие конфликты, называемые коллизиями. После обнаружения конфликта станции задерживают передачу на некоторое время. Это время небольшое и для каждой станции своё. После задержки передача возобновляется. Реально конфликты приводят к уменьшению быстродействия сети только в том случае, если работает порядка 80-100 станций.
Локальная сеть Token Ring. Этот стандарт сети разработан фирмой IBM. В этой сети устройства подключаются к по топологии «звезда». В качестве метода управления доступом станций к передающей среде используется специальный метод - маркерное кольцо (Тоken Ring). Согласно этому методу каждый узел сети, желающий начать передачу, ждет, когда его достигнет маркер – специальное сообщение.
После этого компьютер не отправляет маркер дальше, а задерживает его у себя и начинает передачу данных. Только тогда, когда будет получено подтверждение приема данных, передающий узел посылает маркер дальше, сигнализируя, что сеть свободна.
Метод управления доступом станций к передающей среде предусматривает следующие правила:
¨ все устройства, подключенные к сети, могут передавать данные, только получив разрешение на передачу (маркер);
¨ в любой момент времени только одна станция в сети обладает таким правом;
¨ данные, передаваемые одной станцией, доступны всем станциям сети.
В Тоkеn Ring используются три основных типа пакетов:
¨ Пакет Управление/Данные (англ. Data/Соmmand Frame ). С помощью такого пакета выполняется передача данных или команд управления работой сети.
¨ Маркер (Token). Станция может начать передачу данных только после получения такого пакета. В одном кольце может быть только один маркер и, соответственно, только одна станция с правом передачи данных.
¨ Пакет Сброса (Аbort). Посылка такого пакета вызывает прекращение любых передач.
Локальная сеть Arknet (Attached Resource Computer NETWork ) - простая, недорогая, надежная и достаточно гибкая архитектура локальной сети, разработанная корпорацией Datapoint в 1977 году. Впоследствии лицензию на Аrcnet приобрела корпорация SМС (Standard Microsistem Corporation), которая стала основным разработчиком и производителем оборудования для сетей Аrcnet.
По технологии Arcnet один из компьютеров создаёт специальный маркер (сообщение специального вида), который последовательно передаётся от одного компьютера к другому. Если станция желает передать сообщение другой станции, она дожидается маркера и добавляет к нему сообщение, дополненное адресами отправителя и назначения. присоединяет к маркеру свое сообщение и посылает его дальше. Следующий узел также может присоединить к группе свое сообщение и т.д. В результате по сети проходит поток из нескольких сообщений, возглавляемых кольцевым маркером.
Компьютер, которому адресовано одно из сообщений потока, отцепляет его.Когда пакет дойдёт до станции назначения, сообщение будет «отцеплено» от маркера и передано станции. При подключении устройств в Аrcnet применяют топологии шина и звезда.
Метод управления доступом станций к передающей среде предусматривает следующие правила:
¨ все устройства, подключенные к сети, могут передавать данные, только получив разрешение на передачу (маркер);
¨ в любой момент времени только одна станция в сети обладает таким правом;
¨ данные, передаваемые одной станцией, доступны всем станциям сети.
Передача каждого байта в Аrcnet выполняется специальной посылкой, состоящей из трех служебных старт/стоповых битов и восьми битов данных. В начале каждого пакета передается начальный разделитель АВ (Аlегt Вurst), который состоит из шести служебных битов. Начальный разделитель выполняет функции преамбулы пакета. В Аrcnet определены 5 типов пакетов:
¨ Пакет IТТ (Information To Transmit) - приглашение к передаче. Эта посылка передает управление от одного узла сети другому. Станция, принявшая этот пакет, получает право на передачу данных.
¨ Пакет FBE (Free Buffeг Еnquiries) - запрос о готовности к приему данных. Этим пакетом проверяется готовность узла к приему данных.
¨ Пакет данных. С помощью этой посылки производиться передача данных.
¨ Пакет АСК (ACKnowledgments) - подтверждение приема. Подтверждение готовности к приему данных или подтверждение приема пакета данных без ошибок, т.е. в ответ на FBE и пакет данных.
¨ Пакет NAK ( Negative AcKnowledgments) - неготовность к приему. Неготовность узла к приему данных (ответ на FBE) или принят пакет с ошибкой.
Телекоммуникационные системы – основные функции и компоненты
Термин «локальная сеть» характеризует масштаб сети: количество компьютеров в сети максимум несколько сотен, длина каналов связи обычно не превышает нескольких сотен метров, пропускная спосбность каналов связи достаточно высокая. Основным преимуществом работы в локальной сети по сравнению с работой на отдельных компьютерах является использование в многопользовательском режиме общих ресурсов сети: дисков, принтеров, модемов, программ и данных, хранящихся на общедоступных дисках, а также возможность передавать информацию с одного компьютера на другой. Благодаря вычислительным сетям пользователи получают возможность доступа к ресурсам не только своего, но и остальных компьютеров сети. Понятие локальная вычислительная сеть - относится к географически ограниченным ( территориально или производственно) аппаратно-программным реализациям, в которых несколько компьютерных систем связанны друг с другом с помощью соответствующих средств коммуникаций. Благодаря такому соединению пользователь может взаимодействовать с другими рабочими станциями, подключенными к этой ЛВС.
Локальная вычислительная сеть на предприятии должна выполнять следующие функции:
¨ создание единого информационного пространства, которое способно включать и предоставлять всем пользователям информацию, полученную в разное время и из разных источников;
¨ распараллеливание и контроль выполнения работ и обработки данных по ним;
¨ повышение достоверности информации и надежности ее хранения путем создания устойчивой к сбоям и потерям информации вычислительной системы, а также создание архивов данных, которые можно использовать для аналитической обработки;
¨ обеспечение эффективной системы накопления, хранения и поиска технологической, технико-экономической и финансово-экономической информации по текущей работе и проделанной некоторое время назад (информация архива) с помощью создания глобальной базы данных;
¨ обработка документов и построения на базе этого действующей системы анализа, прогнозирования и оценки;
¨ обстановки с целью принятия оптимального решения и выработки глобальных отчетов;
¨ обеспечение прозрачного доступа к информации авторизованному пользователю в соответствии с его правами и привилегиями.
Существует два подхода к организации сетевого программного обеспечения -сети с централизованным управлением и одно-ранговые сети.
В сети с централизованным управлением выделяются одна или несколько выделенных машин, управляющих обменом данными по сети. Диски выделенных машин, которые называются файл-серверами, доступны всем остальным компьютерам сети. На файл-серверах должна работать специальный мультизадачный диспетчер, использующий защищённый режим работы процессора. Остальные компьютеры называются рабочими станциями. Рабочие станции имеют доступ к дискам файл-сервера и совместно используемым принтерам, но и только. С одной рабочей станции нельзя работать с дисками других рабочих станций. С одной стороны, это хорошо, так как пользователи изолированы друг от друга и не могут случайно повредить чужие данные. С другой стороны, для обмена данными пользователи вынуждены использовать диски файл-сервера, создавая для него дополнительную нагрузку. Есть, однако, специальные программы, работающие в сети с централизованным управлением и позволяющие передавать данные непосредственно от одной рабочей станции к другой, минуя файл-сервер (например, NetLink). После её запуска на двух рабочих станциях можно передавать файлы с диска одной станции на диск другой. На рабочих станциях установливается специальное программное обеспечение, часто называемое сетевой оболочкой. Это обеспечение работает в среде той операционной системы, которая используется на данной рабочей станции.
Файловый сервер выполняет три важные функции:
¨ хранит часто используемые программы;
¨ принимает информацию, которую нужно переслать от одной рабочей станции к другой рабочей станции;
¨ служит шлюзом (передающим устройством) к другим сетям.
Файл-серверы могут быть выделенными или невыделенными. В первом случае файл-сервер не может использоваться как рабочая станция и выполняет только задачи управления сетью. Во втором случае параллельно с задачей управления сетью файл-сервер выполняет обычные пользовательские программы. Однако при этом снижается производительность файл-сервера и надёжность работы всей сети в целом, так как ошибка в пользовательской программе, запущённой на файл-сервере, может привести к остановке работы всей сети.
Программные средства и данные общего назначения (базы данных и клиентские приложения) хранятся в единственном экземпляре на дисках файлового сервера. Благодаря указанной возможности , во-первых, обеспечивается рациональное использование внешней памяти за счёт освобождения локальных дисков рабочих станций, и во-вторых, облегчается поддерхка целостности данных, что всегда является проблемой при дублировании информации.
Файловый сервер, связанный с глобальной сетью, может обеспечить доступ пользователя с любого компьютера локальной сети к ресурсам глобальных сетей.
Рабочие станции, входящие в ЛВС, могут быть разделены на рабочие группы. Рабочей группе можно выделить свои ресурсы (накопители, принтеры, программное обеспечение, которые будут недоступны другим рабочим группам).
Существуют различные сетевые операционные системы, ориентированные на сети с централизованным управлением. Самые известные из них - Novel NetWare, Microsoft Lan Manager (на базе OS/2), а также выполненная на базе UNIX сетевая операционная система VINES.
Одно-ранговые сети не содержат в своём составе выделенных серверов. Функции управления сетью передаются по очереди от одной рабочей станции к другой. Как правило, рабочие станции имеют доступ к дискам (и принтерам) других рабочих станций. Такой подход облегчает совместную работу групп пользователей, но в целом производительность сети может понизиться.
Одно из достоинств одно-ранговых сетей - простота обслуживания. Если для обслуживания сети на базе Novel NetWare, как правило, требуется системный администратор, то для поддержания работоспособности одно-ранговой сети не требуется специально выделенный для этого сотрудник.
В сети иногда возникают конфликты при попытке разных станций передать данные по одному каналу связи. Это приводит к перебоям в передаче и в конечном счете к уменьшению пропускной способности сети. Поэтому важной характеристикой сети служат методы разрешения конфликтных ситуаций.
Пользователи локальной сети обычно получают и передают информацию разной степени важности, поэтому более важное сообщение должно иметь возможность передаваться по каналу связи вне очереди. Третьим критерием можно считать систему приоритетов.
При большой загрузке сети необходимо как можно более полное использование каналов связи, что обеспечивается правильным управлением сетью и возможностью работы в загруженных сетях.
Один из подходов к управлению сетью заключается в том, что один из компьютеров сети выделяется в качестве главного узла. Главный узел управляет всеми остальными компьютерами, подключенными к сети, и сам определяет, какие устройства и когда производят передачу информации.
Второй подход реализуется на основе равнорангового (одноуровнего) протокола. При этом подходе все компьютеры сети имеют в принципе одинаковый статус (хотя фактически они могут иметь разные права доступа). Возможно и применение гибридных (смешанных) систем.
Поскольку для ЛВС характерны небольшие значения времени распространения сигналов и высокие скорости работы каналов, а также небольшое количество ошибок, не требуется, чтобы в локальной сети использовались сложные протокольные механизмы соединения, опроса, выбора, положительного (или отрицательного) подтверждения.
При организации взаимодействия узлов в локальных сетях основная роль отводится протоколу канального уровня. Наиболее популярный протокол канального уровня - Ethernet - рассчитан на параллельное подключение всех узлов сети к общей для них шине - отрезку коаксиального кабеля.
Подход, заключающийся в использовании простых структур кабельных соединений между компьютерами локальной сети, являлся следствием основной цели, которую ставили перед собой разработчики первых локальных сетей во второй половине 70-х годов. Эта цель заключалась в нахождении простого и дешевого решения для объединения нескольких десятков компьютеров, находящихся в пределах одного здания, в вычислительную сеть. Решение должно было быть недорогим, потому что в сеть объединялись недорогие компьютеры. Количество их в одной организации было небольшим, поэтому предел в несколько десятков (максимум - до сотни) компьютеров представлялся вполне достаточным для роста практически любой локальной сети.
Для упрощения и, соответственно, удешевления аппаратных и программных решений разработчики первых локальных сетей остановились на совместном использовании кабелей всеми компьютерами сети в режиме разделения времени. Наиболее явным образом режим совместного использования кабеля проявляется в сетях Ethernet, где коаксиальный кабель физически представляет собой неделимый отрезок кабеля, общий для всех узлов сети. Но и в сетях Token Ring, где каждая соседняя пара компьютеров соединена, казалось бы, своими индивидуальными отрезками кабеля, эти отрезки не могут использоваться компьютерами, которые непосредственно к ним подключены, в произвольный момент времени. Эти отрезки образуют кольцо, доступ к которому как к единому целому может быть получен только по вполне определенному алгоритму, в котором участвуют все компьютеры сети. Использование кольца как общего разделяемого ресурса упрощает алгоритмы передачи по нему кадров, так как в каждый конкретный момент времени кольцо используется только одним компьютером.
Такой подход позволяет упростить логику работы сети. Например, отпадает необходимость контроля переполнения узлов сети кадрами от многих станций, решивших одновременно обменяться информацией. В глобальных сетях, где отрезки кабелей, соединяющих отдельные узлы, не рассматриваются как общий ресурс, такая необходимость возникает, и для решения этой проблемы в алгоритмы обмена информацией вводятся весьма сложные процедуры, предотвращающие переполнение каналов связи и узлов сети.
Использование в локальных сетях очень простых конфигураций (общая шина и кольцо) наряду с положительными имело и негативные стороны, из которых наиболее неприятными были ограничения по производительности и надежности. Наличие только одного пути передачи информации, разделяемого всеми узлами сети, в принципе ограничивало пропускную способность сети пропускной способностью этого пути (к тому же разделенной на число компьютеров сети), а надежность сети - надежностью этого пути. Поэтому по мере повышения популярности локальных сетей и расширения их сфер применения все больше стали применяться специальные коммуникационные устройства - мосты и маршрутизаторы - которые в значительной мере снимали ограничения единственной разделяемой среды передачи данных. Базовые конфигурации в форме общей шины и кольца превратились в элементарные структуры локальных сетей, которые можно теперь соединять друг с другом более сложным образом, образуя параллельные основные или резервные пути между узлами.
Тем не менее, внутри базовых структур по-прежнему работают все те же протоколы разделяемых единственных сред передачи данных, которые были разработаны более 15 лет назад. Это связано с тем, что хорошие скоростные и надежностные характеристики кабелей локальных сетей удовлетворяли в течение всех этих лет пользователей небольших компьютерных сетей, которые могли построить сеть без больших затрат только с помощью сетевых адаптеров и кабеля. К тому же колоссальная инсталляционная база оборудования и программного обеспечения для протоколов Ethernet и Token Ring способствовала тому, что сложился следующий подход - в пределах небольших сегментов используются старые протоколы в их неизменном виде, а объединение таких сегментов в общую сеть происходит с помощью дополнительного и достаточно сложного оборудования.
Типы сервисов Интернет
Передачу информации согласно протоколам TCP/IP используют разнообразные сервисы Интернет. Эффективность работы в сети определяется умением обращаться с конкретными сервисами и способностью выбрать правильный способ решения конкретной задачи. Этим определяется не только то, как скоро Вы сможете найти нужную информацию, но и то, сможете ли Вы ее найти вообще.
Принято делить сервисы Интернет на сервисы интерактивные, прямые и отложенного чтения. В сервисах отложенного чтения запрос и получение информации разделены по времени. Сюда относится, например, электронная почта. Сервисы прямого обращения характерны тем, что информация по запросу возвращается немедленно. Однако от получателя информации не требуется немедленной реакции. Сюда можно отнести передачу FTP-файлов. Сервисы, где требуется немедленная реакция на полученную информацию, относятся к интерактивным сервисам. Таким сервисом является WWW.
Топология локальной сети
Топологией локальной сети называется способ и технология соединения ее узлов. Принято различать ттопологию в форме звезды, кольцевую топологию и щинную топологию.
Топология типа звезда.
Концепция топологии сети в виде звезды пришла из области больших ЭВМ, в которой головная машина получает и обрабатывает все данные с периферийных устройств как активный узел обработки данных. Один узел является центральным. Он соединен каналами связи со всеми остальными узлами, которые обычно называются рабочими станциями. Каждый канал входит в центральный узел через свой сетевой адаптер. Благодаря этому связь рабочей станции с центральным узлом независима от связей остальных станций. Вся информация между двумя периферийными рабочими местами проходит через центральный узел вычислительной сети. Пропускная способность сети определяется вычислительной мощностью узла и гарантируется для каждой рабочей станции. Коллизий (столкновений) данных не возникает. Затраты на прокладку кабелей высокие, особенно когда центральный узел географически расположен не в центре топологии. При расширении вычислительных сетей не могут быть использованы ранее выполненные кабельные связи: к новому рабочему месту необходимо прокладывать отдельный кабель из центра сети.
Топология в виде звезды является наиболее быстродействующей из всех топологий вычислительных сетей, поскольку передача данных между рабочими станциями проходит через центральный узел (при его хорошей производительности) по отдельным линиям, используемым только этими рабочими станциями. Частота запросов передачи информации от одной станции к другой невысокая по сравнению с достигаемой в других топологиях. Производительность вычислительной сети в первую очередь зависит от мощности центрального узла. Он может быть узким местом вычислительной сети. В случае выхода из строя центрального узла нарушается работа всей сети.
Центральный узел управления в случае топологии типа звезды может реализовать оптимальный механизм защиты против несанкционированного доступа к информации, так как вся вычислительная сеть управляется из ее центра.
Кольцевая топология. При кольцевой топологии сети рабочие станции связаны одна с другой по кругу. По-одному сетевому адаптеру компьютер принимает сообщение от одной станции, а по другому сетевому адаптеру он это сообщение отправляет. Прокладка кабелей от одной рабочей станции до другой может быть довольно сложной и дорогостоящей, особенно если географически рабочие станции расположены далеко от кольца (например, в линию).
Сообщения циркулируют регулярно по кругу. Рабочая станция посылает по определенному конечному адресу информацию, предварительно получив из кольца запрос. Пересылка сообщений является очень эффективной, так как большинство сообщений можно отправлять по кабельной системе одно за другим. Очень просто можно сделать кольцевой запрос на все станции. Продолжительность передачи информации увеличивается пропорционально количеству рабочих станций, входящих в вычислительную сеть.
Основная проблема при кольцевой топологии заключается в том, что каждая рабочая станция должна активно участвовать в пересылке информации, и в случае выхода из строя хотя бы одной из них вся сеть парализуется. Неисправности в кабельных соединениях локализуются легко. Подключение новой рабочей станции требует кратко срочного выключения сети, так как во время установки кольцо должно быть разомкнуто. Ограничения на протяженность вычислительной сети не существует, так как оно, в конечном счете, определяется исключительно расстоянием между двумя рабочими станциями.
Специальной формой кольцевой топологии является логическая кольцевая сеть. Несколько узлов объединяются в кольцо, а от них раходятся лучи звезды. Отдельные звезды включаются в сеть с помощью специальных коммутаторов (англ. Hub - концентратор), которые по-русски также иногда называют “хаб”. В зависимости от числа рабочих станций и длины кабеля между рабочими станциями применяют активные или пассивные концентраторы. Активные концентраторы дополнительно содержат усилитель для подключения от 4 до 16 рабочих станций.
Пассивный концентратор является исключительно разветвительным устройством (максимум на три рабочие станции). Управление отдельной рабочей станцией в логической кольцевой сети происходит так же, как и в обычной кольцевой сети.
Шинная топология. При шинной топологии среда передачи информации представляется в форме одного канала связи, доступного дня всех рабочих станций, к которому они подключаются. Все рабочие станции имеют право получать и посылать сообщения по сети. Адресат сообщения указывается в самом передаваемом пакете. В ЛВС с шинной технологией может существовать только одна станция, передающая информацию. Ситуация, когда два узла одновременно собираются отправить сообщение, называется коллизией. Для предотвращения коллизий применяется какой-либо способ разрешения конфликтов, называемый шинным арбитражем. Одним из них может служить временной метод разделения, согласно которому для каждой подключенной рабочей станции в определенные моменты времени предоставляется исключительное право на использование канала передачи данных.
Другой способ заключается в широкополосной передаче информации: различные рабочие станции получают свою частоту, на которой эти рабочие станции могут отправлять и получать информацию. Пересылаемые данные модулируются на соответствующих несущих частотах, т.е. между средой передачи информации и рабочими станциями находятся соответственно модемы для модуляции и демодуляции. Техника широкополосных сообщений позволяет одновременно транспортировать в коммуникационной среде довольно большой объем информации.
Характеристики топологий вычислительных сетей приведены в таблице.
|
Характеристики |
Топология |
||
|
Звезда |
Кольцо |
Шина |
|
|
Стоимость расширения |
Незначительная |
Средняя |
Средняя |
|
Присоединение абонентов |
Пассивное |
Активное |
Пассивное |
|
Защита от отказов |
Незначительная |
Незначительная |
Высокая |
|
Размеры системы |
Любые |
Любые |
Ограниченны |
|
Защищенность от прослушивания |
Хорошая |
Хорошая |
Незначительная |
|
Стоимость подключения |
Незначительная |
Незначительная |
Высокая |
|
Поведение системы при высоких нагрузках |
Хорошее |
Удовлетворительное |
Плохое |
|
Возможность работы в реальном режиме времени |
Очень хорошая |
Хорошая |
Плохая |
|
Разводка кабеля |
Хорошая |
Удовлетворительная |
Хорошая |
|
Обслуживание |
Очень хорошее |
Среднее |
Среднее |
Вычислительные сети с древовидной структурой применяются там, где невозможно непосредственное применение базовых сетевых структур в чистом виде. Для подключения большого числа рабочих станций соответственно адаптерным платам применяют сетевые усилители и / или коммутаторы. Коммутатор, обладающий одновременно и функциями усилителя, называют активным концентратором.
Указатели
Перейдем теперь к механизму использования указателей в языке Турбо?Паскаль. Различают нетипизированные и типизированные указатели. Нетипизированный указатель объявляется при помощи предопределенного типа pointer. Значение нетипизированного указателя представляет собой адрес в оперативной памяти. Значение типизированного указателя также представляет собой адрес, но по этому адресу обязано быть размещено данное только определенного типа. Для оперирования с типизированным указателем используется символ “^” (крышка). В разделе объявлений переменных типизированный указатель описывается следующим образом:
<имя переменной-указателя> : ^<имя типа значения указателя>
Например, указатель типа ^integer
ссылается на переменную целого типа, а указатель типа ^rec ссылается на запись типа rec, определенную программистом в разделе типов.
Для того, чтобы значение по адресу, хранящемуся в указателе, использовать в выражении, нужно записать крышку после имени указателя: если переменная n имеет значение 1, а переменная p указывает на n, то выражение p^ равно 1. Используя указатель, можно также присвоить значение по адресу, указанному в указателе: в вышеприведенном примере оператор p^:=5 законен и после него переменная n примет значение 5. Общее правило можно сформулировать следующим образом: если в текущий момент указатель ссылается на некоторую переменную, то использование имени указателя с крышкой после него тождественно использованию имени переменной. Преимущество в использовании указателей заключается в том, что меняя содержимое указателя, одно и то же действие можно сделать с различными переменными и даже с непоименованными значениями.
В Турбо?Паскале имеется унарная операция @, которая присваивает указателю адрес переменной, являющейся операндом операции: p := @n. После выполнения этой операции указатель p
будет указывать на переменную n. Следует отметить, что эта операция не требует, чтобы типы переменной и указателя были согласованы (этим Турбо?Паскаль отличается от стандартного Паскаля).
Однако лучше без необходимости не смешивать переменные различных типов.
Указателю в Паскале можно присвоить значение специальной предопределенной константы с именем Nil
(типа pointer), что означает, что указатель не имеет определенного значения и на него нельзя ссылаться.
Использование указателей в Паскале обусловлено двумя различными обстоятельствами. Во-первых, в некоторых задачах использование указателей позволяет унифицировать действия, которые без использования указателей кажутся сложными и запутанными. Сюда можно отнести обработку списков, очередей, деревьев, поддержку индексов массивов. Во-вторых, указатели необходимы при использовании динамической памяти. Зачастую обе указанные причины переплетаются.
Образование динамической переменной в Паскале осуществляется функцией new, параметром которой должен служить типизированный указатель. Функция new выделяет столько байтов, сколько требуется для динамической переменной заданного типа, а адрес начала выделенной памяти присваивает указателю. После этого динамической переменной можно присвоить какое-либо значение. Следует отметить, что единственный доступ к динамической памяти - это содержимое указателя. Достаточно изменить значение указателя - и динамическая переменная потеряна для программы навсегда. После того, как динамическая переменная перестанет быть нужна, ее можно уничтожить (а занятую ею память освободить для дальнейшего использования) функцией dispose. В качестве параметра функции dispose нужно передать указатель, ссылающийся на уничтожаемую динамическую переменную. После уничтожения динамической переменной указатель на нее теряет смысл, хотя значение адреса сохраняется. Хороший стиль программирования заключается том, что после освобождения памяти функцией dispose(p)
указателю p должно быть присвоено значение Nil.
Для пояснения оперирования с указателями приведем несколько примеров. Пусть переменные определены следующим образом:
type
tp1 = array [1..10] of integer;
var
n1,n2: integer;
p1,p2: ^integer
p3: ^real;
p4: ^tp1;
p5: pointer;
После операторов
n1 := 3; n2 := 5; p1 := @n1; p2 := @n2;
указатель p1 будет содержать адрес переменной n1, а указатель p2 будет содержать адрес переменной n2. При этом будет выполняться p1^=3, p2^=5. После присваивания p2:=p1 переменная p2 будет ссылаться на n1 и окажется p2^=3. После присваивания p2^:=1 значение 1 занесется в переменную n1 и теперь окажется p1^=p2^=n1=1, n2=5.
Пусть теперь мы хотим выделить память новым динамическим переменным:
new (p1);
new (p3);
new (p4);
В свободной оперативной памяти выделится 2,6 и 20 байтов для соответственно целой и вещественной переменной и массива из 10 целых чисел, на которые будут ссылаться указатели p1, p3 и p4. Этим переменным пока не присвоено никакого значения. Для занесения значений в динамические переменные мы можем написать примерно следующее
p1^ := 7;
p3^ := 2.75;
p4^[1] := 2;
p4^[8] :=6;
и т.д. Если в дальнейшем присвоить p2:=p1, то указатели p1 и p2 будут ссылаться на одно и то же значение. Если изменить указатель p1 оператором p1:=@n1, то на динамическую переменную будет ссылаться только указатель p2. Если изменить также и его, например, p2:=@n2, то адрес динамической переменной, образованной функцией new, будет потерян навсегда и эту динамическую переменную нельзя будет ни использовать, ни закрыть, в то время как память ею будет занята. Для того, чтобы этого не происходило, надо было предварительно освободить память процедурой dispose(p2).
Указатели можно только присваивать и сравнивать на равенство и неравенство. При этом необходимо следить за согласованностью типов указателей: оператор p1:=p2 и сравнение p1=p2 правильные, а оператор p1:=p3 и сравнение p1=p3 будут считаться синтаксической ошибкой. Однако можно выполнить присваивание в два приема с использованием нетипизированного указателя p5, а именно: p5:=p3; p1:=p5. Аналогично можно сравнивать любой типизированный с нетипизированным указателем.
Управление программами
Предположим, пользователь обращается к операционной системе с требованием запустить определенную программу, передав ей заданные параметры. Разберемся, как это должно происходить.
Прежде всего необходимо разобраться, в каком виде передается информация о программе и ее параметрах. В MS DOS, например, программа задается указанием ее полного имени, включающем все содержащие ее директории, имя программы и его расширение. Параметры могут быть только текстовые, и передаются они в виде слова без пробелов. Первое действие операционной системы заключается в поиске программы на диске. Для этого в таблице размещения файлов отыскивается строка, описывающая файл с указанным именем. В этой строке указан адрес его размещения на диске (номер цилиндра, номер дорожки, номер сектора) и размер. Фактически файл на диске может размещаться несколькими кусками.
Операционная система начинает сначала считывать служебную информацию программы. Она умеет определять, каким способом программа загружается в память (целиком или частями) и сколько пространства ей нужно. После этого в оперативной памяти следует отыскать свободный фрагмент нужного размера. Для этого операционная система должна знать распределение занятой и свободной оперативной памяти в каждый момент времени и уметь найти необходимый участок свободной памяти. Однако прежде, чем переписывать программу с диска в оперативную память, создается служебный блок (префикс программы), который помещается в начало отведенного программе места. В этом блоке помещаются, в частности, параметры программы. И только после служебного блока размещается сама программа.
После этого программа готова к работе. Однако необходимо обеспечить ее нормальную работу и возвращение к операционной системе после окончания работы программы. Точка возвращения (то есть тот адрес, на который следует передать управление после завершения работы программы) записывается в префикс программы. Затем операционная система запоминает текущее содержимое регистров процессора и заполняет регистры теми значениями, которые необходимы для работы программы.
И только после этого производится передача управления на точку входа программы.
Когда программа заканчивает свою работу, все операции производятся в обратном порядке. В префиксе программы отыскивается адрес точки возврата, куда передается управление. Затем восстанавливаются значения регистров процессора, ранее сохраненные. После восстановления содержимого регистров ОС освобождает оперативную память, прежде занятую программой (то есть помечает ее как свободную), после чего продолжает свою работу в обычном режиме (то есть ждет следующей команды).
По той же схеме операционная система обеспечивает вызов подпрограммы из прикладной программы. Здесь может быть несколько возможностей. Подпрограмма может лежать в одном программном сегменте с программой. В этом случае обращения к операционной системе обычно не требуется, а сохранение содержимого регистров и обеспечение возврата к точке вызова берет на себя сама программа. Вторая ситуация связана с наличием у программы так называемой оверлейной структуры, когда несколько программных модулей работают в одном и том же месте оперативной памяти внутри пространства, отведенного программе (таким образом оперативная память экономится). В этом случае программа вынуждена обратиться к ОС для выполнения операции чтения вызываемого модуля с диска в заданную область памяти. Для этого ОС вызывает соответствующую функцию, которая работает как подподпрограмма ОС. После загрузки модуля обеспечивается вызов подпрограммы так же, как это происходило в первом случае.
Еще один случай относится к так называемой динамической загрузке программ. Здесь подпрограмма находится не в памяти, а на диске. В случае обращения к ней операционная система производит примерно те же действия, что и при загрузке основной программы: поиск на диске по имени, выделение свободной памяти, формирование служебного префикса программы, чтение подпрограммы в память, сохранение содержимого регистров, передача параметров, передача управления подпрограмме. После окончания работы подпрограммы ОС выполняет все обратные действия по закрытию программы и только затем передает управление на вызывающую программу.
В операционной системе MS DOS ряд функций по управлению запуском программ связан с ее конструктивными особенностями. В этой ОС существует ограничение на общий объем используемого адресного пространства оперативной памяти (640Кб). В поздних версиях можно использовать дополнительную память (адреса от 640Кб до 1Мб). Специальные утилиты DOS позволяют разместить в этой дополнительной памяти служебные программы DOS и драйверы устройств и использовать их правильно. Прикладные программы размещаются в основной памяти (адреса до 640Кб).
При этом MS DOS не поддерживает мультизадачный режим и фактически в каждый момент времени в памяти размещена только одна прикладная программа. Для одновременного нахождения в памяти служебных программ (такие программы называются резидентными) придуман специальный механизм. Эти программы размещаются несколько отступая от начала основной памяти, а адреса входа в эти программы располагаются в специальном векторе прерываний, который, в свою очередь, расположен в самом начале основной памяти (начиная с нулевого адреса). Чтобы вызвать такую резидентную программу, надо выполнить программное прерывание с номером, соответствующим номеру программы в векторе прерываний. Для того, чтобы защитить пространство, занятое резидентными программами, в ОС имеется специальный параметр, указывающий размер начала основной памяти, занятый резидентными программами.
Резидентной при необходимости можно сделать и пользовательскую программу, надо только помнить, что резидентные программы отнимают память у других программ.
Операционная система Windows использует такой механизм управления оперативной памятью, который позволяет отказаться от ограничений на ее объем. Windows различает виртуальную и реальную оперативную память. Размер виртуальной памяти 4 Гб. Всем работающим под Windows программам предоставляется пространство в виртуальной памяти. В реальной памяти отображается только часть виртуальной памяти, остальная ее часть хранится на диске. Динамические таблицы содержат соответствие между блоками (страницами) виртуальной памяти и их размещением (адресами в реальной памяти или на диске).Если необходимо выполнить ту страницу программы, которая в настоящий момент находится на диске, то эта страница загружается в реальную оперативную память на какое-либо неиспользуемое в настоящий момент место. Предварительно затираемая страница реальной памяти сохраняется на диске. Эта процедура сохранения и чтения страниц называется своппингом (от англ swapping).
Условный оператор
Условный оператор используется тогда, когда в зависимости от значения некоторого выражения нужно выполнить то или иное действие. Условный оператор имеет сложную структуру и состоит из IF?конструкции, THEN?конструкции и ELSE?конструкции. Формат условного оператора следующий:
if <условие> then <оператор1> [ else <оператор2> ]
Условие является выражением, имеющим логическое значение true или false.
Если условие в тот момент, когда выполняется данный условный оператор, истинно, должен быть выполнен <оператор1>, в противном случае выполняется <оператор2>. ELSE?конструкция в составе условного оператора может опускаться, о чем свидетельствуют квадратные скобки, в которые она заключена. В этом случае при ложности условия не выполняется ничего и происходит переход к следующему оператору. Следует обратить внимание на то, что при наличии ELSE?конструкции употребление точки с запятой после оператора THEN-конструкции будет ошибкой, так точка с запятой в этом случае будет обозначать конец всего условного оператора и ELSE?конструкция будет считаться началом следующего оператора. Другой возможный источник ошибок при использовании условного оператора связан с тем обстоятельством, что в THEN- и ELSE?конструциях должен стоять ровно один оператор. Поэтому, если необходимо, чтобы при истинности или ложности условия выполнилось несколько операторов, из них нужно составить один составной оператор путем заключения в операторные скобки begin . . . end.
Сейчас уместно поговорить о стиле записи текста программы. Дело в том что в Паскале допустимы вложения одна в другую сложных конструкций, таких, как условные операторы или операторы цикла. В результате структура таких конструкций трудно читаема. Для того, чтобы облегчить читаемость текста, каждый программист может следовать определенным правилам записи, называемым стилем записи. Например, условный оператор можно записать в одном из следующих стилей:
if <условие> then <оператор1> else <оператор2> ; {Стиль 1}
if <условие> then <оператор1> {Стиль 2}
else <оператор2> ;
if <условие> then {Стиль 3}
<оператор1>
else <оператор2> ;
if <условие> {Стиль 4}
then <оператор1>
else <оператор2> ;
Первый стиль не пригоден, если THEN- и ELSE-конструкции длинные. Приведем пример условного оператора, содержащего составные операторы, записанного одним стилем:
if <условие> then
begin
<оператор1> ;
<оператор2>
end
else
begin
<оператор3> ;
<оператор4>
end;
и другим стилем:
if <условие>
then
begin
<оператор1> ;
<оператор2>
end
else
begin
<оператор3> ;
<оператор4>
end;
Каждый из стилей имеет свои достоинства и недостатки.
Устройства ввода информации
Устройства ввода информации в компьютер очень разнообразны. К ним относятся клавиатура, мышь, трекбол, джойстик, сканер, диджитайзер, устройство распознавания речи и т.д. Кроме того, существуют специализированные устройства ввода, автоматически преобразуюшие информацию для ввода ее в компьютер, например, датчики от технических устройств.
Клавиатура является пока основным устройством ввода информации в персональный компьютер. В техническом аспекте это устройство представляет собой совокупность механических датчиков, воспринимающих давление на клавиши и замыкающих тем или иным способом определённую электрическую цепь. В логическом плане клавиатура просто передает в компьютер сообщения о действиях пользователя. Типов действия всего два: нажать клавишу и отпустить ее.
Фактически в компьютер передается номер клавиши и вид действия. Для того, чтобы увеличить количество возможных номеров клавиш для передачи в компьютер, в клавиатуре аппаратно реализована возможность менять номер клавиши в том случае, если при этом будут нажаты другие специально выделенные для этого клавиши, такие, как «Shift», «Ctrl» или «Alt» (это в клавиатуре, предназначенной для IBM PC). Кроме того, другие клавиши, такие как «Caps Lock» или «Num Lock» меняют состояние клавиатуры, заставляя ее выдавать при нажатии клавиши другой номер.
Передаваемый в компьютер номер клавиши занимает один байт и поэтому его величина изменяется от 0 до 255. Вариантов нажатия клавиш с учетом комбинаций значительно больше. Поэтому в компьютер передается либо номер нажатия, отличный от нуля, либо передаются два числа, первое из которых равняется нулю (что и служит признаком чтения следующего числа). Таким образом, возможных вариантов нажатий клавиш всего не более 510.
Расположение клавиш на клавиатуре и их номера видоизменялись с течением времени. Надо сказать, что эволюция клавиатур для IBM PC не была долгой. Сначала использовались 83-х клавишные клавиатуры, затем вместе с АТ появилась 84-х клавишная. Подавляющее большинство современных IBM PC совместимых используют расширенную клавиатуру.
Основные улучшения по сравнению с АТ- клавиатурой касается общего числа клавиш (101 и выше) и их расположения. Стандартным является расположение QWERTY, содержащее порядка 60 клавиш с буквами, цифрами, знаками пунктуации и другими символами и ещё около 40 функциональных клавиш.
В настоящее время наиболее распространены два вида клавиатур: с механическими и мембранными переключателями. В первом случае датчик представляет собой традиционный механизм с контактами из специального сплава. Несмотря на то, что эта технология используется уже несколько десятилетий, фирмы-производители постоянно работают над её модификацией и улучшением. Стоит отметить, что в клавиатурах известных фирм контакты переключателей позолоченные, что значительно улучшает электрическую проводимость. Технология, основанная на мембранных переключателях, считается более прогрессивной, хотя особых преимуществ не даёт.
Мыши и трекболы являются координаторными устройствами ввода информации в компьютер. Разумеется, полностью заменить клавиатуру они не могут. Технически мышь содержит резиновый шарик в нижней части и две или три кнопки управления. При перемещении шарика по твердой поверхности шарик крутится и передает вращение на два колесика (иногда три), одно из которых соответствует горизонтальному перемещению, а другое – вертикальному. Перемещение мыши по столу отражается пропорциональным перемещением на экране специального указателя – курсора мыши. При положении курсора в определенном месте экрана пользователь может нажать или отпустить одну из кнопок мыши.
Логически мышь передает в компьютер сообщения о следующих событиях: поворот колесика на определенное минимальное значение угла, нажатие и отпускание кнопки мыши. Эти сообщения передаются в компьютер в виде кодов, там обрабатываются и затем реализуются в форме адекватных действий. От минимального угла зависит разрешение мыши. Оно измеряется в количестве различаемых точек на дюйм (cpi). Современные мыши имеют обычно оптимальное аппаратное разрешение 400 cpi.
Когда фирмы декларируют разрешение на уровне 1800 cpi, то речь идёт о программном разрешении.
Трекбол представляет собой «перевёрнутую» мышь: трекбол закреплен, а крутится у него только его шар. Это позволяет существенно повысить точность управления курсором.
Джойстик представляет собой рычаг, закрепленный на подставке, способный перемещаться на шарнирах в двух направлениях. Подобно мыши, он передает в компьютер сдвиги в каждом направлении и нажатие на клавишу на верхушке джойстика.
Сканер предназначен для ввода в компьютер текстовой и графической информации непосредственно с изображения. Изображение разбивается на точки, которые считываются с помощью оборудования, аналогичного тому, которое употребляется при ксерокопировании. Если сканируется текст, то он обрабатывается специальными программами распознавания текста. Эти программы очень сложны.
Электронный планшет (или диджитайзер) является координирующим преобразователем, который используется в основном для задач САПР. В состав диджитайзера помимо самого планшета входит специальный указатель с датчиком. Горизонтальное и вертикальное перемещения датчика передаются в компьютер для определения координат считываемой на планшете точки. Сама точка считывается с помощью оборудования, аналогичного тому, которое употребляется при ксерокопировании.
Устройство распознавания речи передает в компьютер звуки, закодированные особым образом. Там они распознаются с помощью специальной программы и преобразуются в текст.
Устройства вывода информации
Устройства вывода информации предназначены для представления результатов работы компьютера в «человеческом» виде. Кроме видеомонитора, о котором шла речь выше, это принтер, предназначенный для бумажной печати тестовой и графической информации, плоттер (или графопостроитель), предназначенный для печати графиков и чертежей, и звуковые колонки.
Управление работой большинством устройств ввода-вывода компьютера осуществляется при помощи портов. Напомним, что портом называется виртуальная ячейка, соответствующая внешнему входу (или выходу) в компьютере. Конкретному устройству приписывается несколько портов, каждый из которых описывает один из элементов управления устройством. Для процессора операция ввода-вывода представляет собой просто пересылку данных из порта или в порт. Для внешнего устройства любой блок данных, переданный процессором в порт, является некоторой командой или данными, которые надо использовать по назначению (то есть назначению данного устройства). Посылая в определенные порты определенные данные, можно опросить устройство или перевести его в то или иное состояние. Например, посылая определенные числа в определенные порты, приписанные принтеру, можно узнать, подключен ли он, готов ли к печати, есть ли в нем бумага. Из другого порта читаются ответы принтера или сообщения, например, о том, что застряла бумага. Еще один порт предназначен для непосредственной передачи данных для печати.
Принтер является основным средством бумажного вывода. Принтеры бывают последовательные, строчные и страничные. По принципу действия различают принтеры ударного и безударного действия. По способу печати принтеры делятся на матричные и символьные.
Матричные принтеры ударного действия содержат вертикальный ряд игл или молоточков (иногда 2 ряда), которые вколачивают краситель с ленты прямо в бумагу, формируя последовательно символ за символом. Игольчатые принтеры имеют приемлемое качество печати, невысокую цену самого устройства, а также расходных материалов и бумаги.
Для этих принтеров обычно возможно использование как форматной, так и рулонной бумаги. Головка принтера может быть оснащена 9, 18 или 24 иголками.
Существуют модели принтеров как с широкой (А3), так и с узкой (А4) кареткой. Высокое качество печати достигается для 24-игольчатых принтеров. Скорость печати для высокопроизводительных моделей может составлять до 380 знаков в секунду. Более высокую производительность обеспечивают построчные (постраничные) матричные принтеры. Вместо маленьких точечно-матричных головок они используют длинные массивы с большим количеством игл, при этом достигается скорость порядка 1500 строк в минуту. Матричные ударные печатающие устройства создают много шума, что является существенным недостатком.
Струйные принтеры относятся к безударным печатающим устройствам и работают практически бесшумно. Струйные чернильные принтеры относятся к классу последовательных матричных безударных печатающих устройств. Они же в свою очередь подразделяются на устройства непрерывного и дискретного действия. Последние же могут использовать либо пузырьковую технологию, либо пьезоэффект. При печати высокого качества скорость вывода не превосходит обычно 2-3 (около 200 знаков в секунду), хотя максимальные значения могут достигать даже 7 страниц в минуту. Как правило, струйные принтеры позволяют эмулировать работу наиболее популярных моделей ударных устройств и поддерживать соответствующее программное обеспечение.
В лазерных принтерах используется электрографический способ создания изображения - примерно такой же, как и в ксероксах. Кроме лазерных существуют LED-принтеры, которые получили своё название из-за того, что полупроводниковый лазер в них был заменён «гребёнкой» мельчайших светодиодов.
Плоттер – это фактически большой принтер, специально ориентированный на построение чертежей. Он ориентирован на работу со специальными программами систем проектирования (САПР). Принципы его действия те же, что и у принтера.
Почти любой персональный компьютер имеет сейчас в своем составе специальную звуковую плату или аудио-адаптер или “саундбластер”.
Аудио- адаптер представляет собой преобразователь цифровой информации в сигналы, которые генерируют звук в системе воспроизведения. Аудио-адаптер содержит аналого–цифровой преобразователь и цифро–аналоговый преобразователь. Аналого-цифровой преобразователь измеряет через определенные промежутки времени частоту и уровень звукового сигнала и превращает их в цифровой код. Полученный цифровой код записывается на внешний носитель.
Цифровые коды реального звукового сигнала хранятся в памяти компьютера. Поданный на цифро-аналоговый преобразователь цифровой сигнал преобразуется в аналоговые сигналы. После фильтрации их можно усилить и подать на акустические колонки для воспроизведения.
Важными параметрами аудио-адаптера являются частота квантования звуковых сигналов и разрядность квантования. Частоты квантования показывают, сколько раз в секунду берутся выборки сигнала для преобразования в цифровой код. Обычно они лежат в пределах от 4–5 Кгц до 45–48 Кгц. Разрядность квантования характеризует число кодируемых уровней звукового сигнала и измеряется степенью числа 2. Сейчас применяются в основном 16-разрядные аудио-адаптеры, имеющие 216 = 65536 ступеней квантования — как у звукового компакт–диска.
Внешние запоминающие устройства
Данные, хранящиеся в оперативной памяти компьютера, не сохраняются при выключении электропитания. Уже в самых первых компьютерах возникла необходимость постоянного хранения данных. Для этого использовались перфокарты и перфоленты, затем магнитные ленты и магнитные барабаны. К настоящему времени для постоянного хранения данных используются магнитные и лазерные диски. Устройства для чтения и записи на такие диски называются устройствами внешней памяти. Любой персональный компьютер включает накопители на гибких магнитных дисках (НГМД) и накопители на жестких магнитных дисках (НМД или винчестер). Большинство содержат также устройство для работы с лазерными дисками (CD-ROM).
В магнитных дисках информация записывается на вращающихся дисках, покрытых магнитным материалом. Поверхность диска условно разбита на концентрические круги – дорожки. Радиус диска называется цилиндром. Пересечение дорожки и цилиндра является элементарной единицей для хранения одного бита информации по принципу: «намагничено» – 1, «не намагничено» - 0. Таким образом, все дорожки имеют одинаковую емкость (содержат одинаковое число бит). Обычно дорожки делятся на блоки данных объемом 512 байт, иногда называемые секторами. Количество секторов, записываемых на одну дорожку, зависит от физических размеров пластины и плотности записи.
Для чтения или записи информации используется специальная магнитная головка, которая может перемещаться по радиальной оси к центру или от центра диска, останавливаясь над любой дорожкой диска. В НГМД магнитные головки касаются поверхности флоппи-дисков. Данные на дорожке просматриваются компьютером последовательно по мере вращения диска. Конструктивно НГМД выполнен таким образом, что установленные в нем магнитные диски можно менять. Сменные магнитные диски называются гибкими магнитными дисками или флоппи-дисками (их также называют дискетами). Гибкие дискеты позволяют переносить документы и программы с одного компьютера на другой, хранить информацию, не используемую постоянно на компьютере, делать архивные копии информации, содержащейся на жёстком диске.
Жесткий диск (винчестер) состоит на самом деле из нескольких (4-9) дисков с магнитным покрытием, вращающихся на общем валу. Для записи данных используются обе поверхности дисков. Вал постоянно вращается с высокой скоростью (обычно 3600 - 7200 оборотов в минуту). Данные записываются или считываются с помощью головок записи/считывания, по одной на каждую поверхность каждого диска. Специальный двигатель на каретке позиционирует головку над заданной дорожкой. Накопитель на магнитных дисках (НМД) представляет собой набор дисков, магнитных головок, кареток, линейных двигателей плюс воздухонепроницаемый корпус. Дисковым устройством называется НМД с относящимися к нему электронными схемами.
Производительность диска включает в себя три основных характеристики: время доступа, время ожидания и время передачи данных. Время доступа - это время, необходимое для позиционирования головок на соответствующую дорожку, содержащую искомые данные. Оно зависит от начального ускорения головки (порядка 6 мс) и числа дорожек, которые необходимо пересечь на пути к искомой дорожке. Среднее время перемещения головки между двумя случайно выбранными дорожками лежат в диапазоне 10-20 мс. Время перехода с дорожки на дорожку меньше 10 мс и обычно составляет 2 мс.
Временем ожидания называется среднее время оборота диска до появления под головкой диска нужного сектора. После этого данные могут быть записаны или считаны. Для современных дисков время полного оборота лежит в диапазоне 8-16 мс, а среднее время ожидания составляет 4-8 мс.
Время передачи данных, т.е. время, необходимое для физической передачи байтов, зависит от числа передаваемых байтов (размера блока), скорости вращения, плотности записи на дорожке и скорости электроники. Типичная скорость передачи равна 1-4 Мбайт/с.
Рассмотрим типичную подсистему ввода-вывода. Такая подсистема включает в себя четыре основных компонента: основной компьютер, главный адаптер, встроенный в дисковое устройство контроллер и собственно накопитель на магнитных дисках.
Когда операционная система получает запрос от пользователя на выполнение операции ввода/вывода, она превращает этот запрос в набор команд главного адаптера. Эти команды пересылаются по системе шин в главный адаптер, после чего процессор отключается от дальнейших операций.
Главный адаптер запрашивает дисковый контроллер о его готовности. Если тот готов, то главный адаптер пересылает ему соответствующую команду. Если контроллер может выполнить команду немедленно, то он пересылает в главный адаптер запрошенные данные (при вводе) или свое состояние (при выводе). Команда ввода может быть обслужена немедленно, только если данные уже находятся в кэш-памяти контроллера. Если это не так, то нужные данные переписываются с диска в кэш-память контроллера. При записи подтверждение записи не поступает в контроллер до тех пор, пока данные действительно не перепишутся из кэш-памяти контроллера на поверхность диска.
После завершения операции ввода/вывода контроллер диска соединяется с главным адаптером, вслед за чем выполняется либо передача данных из контроллера в главный адаптер при вводе, либо указание результата операции при выводе. При выводе главный адаптер проверяет корректность завершения физической операции в контроллере и соответствующим образом информирует операционную систему. Можно сделать вывод, что ввод и вывод информации на внешний носитель содержат большое количество шагов, которые обычно не видны пользователю.
В лазерных дисковых накопителях используется чисто оптический способ кодирования информации. Аналогично магнитным дискам, лазерные диски разбиты на дорожки, однако запись единицы на дорожку диска производится за счет изменения отражающих свойств поверхности. Наиболее употребительны лазерные диски, основанные на механическом изменении рельефа дорожки. Луч лазера направляется на дорожку, проникает сквозь защитный слой пластика и попадает на отражающий слой алюминия на поверхности диска. При попадании луча на выступ, он отражается на детектор и проходит через призму, отклоняющую его на светочувствительный диод.
Если луч попадает в ямку, он рассеивается и лишь малая часть излучения отражается обратно и доходит до светочувствительного диода. На диоде световые импульсы преобразуются в электрические, при этом яркий луч преобразуется в нули, слабый луч - в единицы. Таким образом, ямки воспринимаются дисководом как нули, а гладкая поверхность - как единицы
Существуют три разных типа лазерных накопителей. Диски первого типа можно только читать. Эти накопители работают как сменное ПЗУ и называются CD-ROM. Компакт-диски для накопителей CD-ROM изготавливаются промышленным способом, однако существует специальное устройство, позволяющее записывать лазерные диски самому. Второй тип лазерных накопителей позволяет записывать информацию на лазерный диск только один раз. Это так называемые WORM-накопители. Их удобно использовать для работы с большими объемами редко изменяющейся, но пополняющейся информации, такой как, например, каталоги больших библиотек. Самый удобный, но и самый дорогой тип лазерных накопителей - накопители с перезаписью. Они основаны на других физических принципах и при емкости и быстродействии, сравнимом с быстродействием НМД, пока стоят очень дорого. Однако высокая надежность и возможность смены дисков с данными делают их весьма привлекательными, если необходимо работать с очень большими объемами данных.
Очень редко теперь используются накопители на магнитной ленте или стримеры. По своему принципу действия эти устройства напоминают бытовые кассетные магнитофоны. Чаще всего стримеры используют для резервного копирования содержимого НМД, что позволяет избежать потери данных при выходе НМД из строя. Самые хорошие стримеры позволяют записать на одну кассету с магнитной лентой до 2 Гбайт информации, однако из-за высокой стоимости таких стримеров больше распространены стримеры с кассетами, рассчитанными на запись 150 или 250 Мбайт данных.
Операция ввода - вывода активизируется текущей командой программы или запросом от периферийного устройства ввода - вывода. При программном управлении передачей данных процессор "отвлекается" от выполнения основной программы на все время операции ввода - вывода, следовательно, снижается производительность компьютера.Для ввода блока данных необходимо слишком много операций, таких как преобразование форматов, адресация в памяти, определение начала и конца блока данных. В результате скорость передачи данных снижается.
Более выгоден обмен данными с использованием прямого доступа к памяти (DMA). При этом процессор освобождается от участия в передаче данных и может параллельно выполнять основную программу. Специальное устройство берет на себя управление обменом данных между оперативной памятью и внешними устройствами. Инициатором обмена данными в этом случае является периферийное устройство, которое посылает запрос об обмене данными на устройство DMA. Последнее, получив предварительно от процессора сигнал подтверждения, посылает в память сигнал чтения или записи и определяет ячейку памяти, с которой начнется обмен данными. Далее происходит обмен данными между оперативной памятью и внешним устройством.
VRML
Аббревиатура VRML расшифровывается как "язык описания виртуальной реальности". Это язык описания трехмерных сцен и объектов. Через World Wide Web пользователь может получить файл в формате VRML, и, если программа-клиент обладает такой возможностью, просматривать сцену с разных точек зрения. При этом картинка на экране остается плоской, но, перемещая точку обзора, пользователь может наблюдать вид трехмерного объекта с разных сторон.
Основная проблема этой технологии заключается в том, что обработка VRML-файлов происходит на компьютере пользователя и требует значительных вычислительных и графических ресурсов. Поэтому, с одной стороны, программ-клиентов, поддерживающих VRML, не так уж много, и до сих пор нет стандартной программы для этого, доступной на различных платформах. С другой стороны, использование значительных ресурсов компьютера пользователя противоречит идеологии развития технологии по пути дешевых и легких Интернет-терминалов, способных только отображать информацию, полученную по сети. С третьей стороны, индустрия движется по законам рынка - существует огромное количество персональных компьютеров, в которые вложены большие деньги, и они, вероятно, будут развиваться в этом направлении и дальше. А коль это так, VRML - хорошее средство утилизации ресурсов ПК, по мощности переросших понятие "персональный".
Ввод и вывод информации в Паскале
Любая программа обязана обмениваться информацией с внешними источниками. Для этого в каждом языке программирования предусматриваются специальные команды или функции. Средства ввода и вывода языка Паскаль достаточно специфичны. Рассмотрим сначала общую концепцию.
В операционной системе MS DOS пржде, чем читать информацию из файла или писать ее в файл, файл должен быть открыт. Процедура открытия заключается в создании в оперативной памяти специального хранилища (буфера) для информации файла, в создании специальной записи описания характеристик файла и присвоении открытому файлу уникального идентификационного номера, согласно которому происходят все операции ввода-вывода, осуществляемые операционной системой. Соответственно этому в Турбо?Паскале разделены операции чтения и записи и операции открытия и закрытия файла. Кроме того, отдельно выделена специфичная для Турбо?Паскаля операция соединения переменной файла с именем файла. Все эти и другие операции ввода-вывода осуществляются в Паскале с помощью специальных функций ввода-вывода. Объединяет эти функции общая файловая переменная f (переменная, объявленная в разделе переменных с
типом file of <тип отдельной записи файла>) .
Функция Assign (f, name) соединяет файл с именем name c файловой переменной f. Это соединение будет существовать до следующего соединения той же файловой переменной с другим файлом. Файловой переменной при объявлении сопоставляется определенный тип отдельной записи файла (не следует смешивать общее понятие записи файла и понятие типа записи языка Паскаль). Проверка корректности соответствия объявленногов Паскале типа записи файла реальному содержимому файла возлагается на программиста.
Функция Rewrite (f) открывает файл, предварительно связанный с файловой переменной f, в режиме “только для записи”. В этом режиме разрешается только заносить информацию в файл. Несуществующий файл при вызове Rewrite создается, а содержимое существующего файла уничтожается. Следует отметить, что в Паскале нельзя открыть файл только для записи, не уничтожив его содержимого.
Исключение делается только для текстового файла, о чем пойдет речь ниже.
Запись информации в файл, открытый функцией Rewrite
(f), из некоторой переменной осуществляется функцией Write (f, <имя переменной>). При этом программист должен следить за тем, чтобы тип переменной и тип записи файла были согласованы. С каждым открытым файлом связывается указатель, который устанавливается на текущую запись или после конца последней записи. Занесение очередной записи производится в место, отмеченное указателем, после чего он располагается после только что занесенной записи файла. Имеется возможность с помощю функции Seek непосредственно установить указатель текущей записи на любую запись.
Функция Reset (f) открывает файл, предварительно связанный с файловой переменной f, в режиме “для чтения и записи”. При открытии файла процедурой Reset текущей становится первая запись. При чтении очередной записи указатель текущей записи сдвигается на следующую запись. Изменяется положение текущей записи с помощью функции Seek.
Чтение информации из файла, открытого функцией Reset (f), в некоторую переменную осуществляется функцией Read (f, <имя переменной>). При этом программист также должен следить за тем, чтобы тип переменной и тип записи файла были согласованы.
Функция Close (f) закрывает файл, связанный с файловой переменной f, не разрывая связи переменной f с именем файла.
Функция Seek (f, number) устанавливает указатель текущей записи на запись с номером number.
Функция Truncate (f) позволяет уничтожить в файле все записи, начиная с текущей. Указатель текущей записи при этом автоматически оказывается установленным на конце файла.
Функция Eof (f) проверяет положение указателя текущей записи в файле, связанном с файловой переменной f. Если этот указатель установлен на конце файла после последней записи или файл пустой, функция Eof (f) возвращает значение true, в противном случае возвращается значение false.
Функция FileSize (f) вычисляет количество записей в файле.
Функция FilePos (f) возвращает номер текущей записи файла.
Очень важное значение в Паскале имеют файлы, состоящие из отдельных символов (то есть файлы типа file of char). Для этих файлов в Турбо?Паскале используется предопределенный тип text. Кроме того, для операций ввода-вывода текстового файла Турбо?Паскаль предоставляет дополнительные возможности. Выражается это в том, что функции read
и write для файла типа text могут считывать и записывать числовую информацию с автоматическим преобразованием в символьный формат. Правила при этом следующие. Функция read читает один символ в переменную типа char, фиксированное число символов в переменную типа string
и символьную запись числа в числовую переменную. Возможно также прочесть за один вызов несколько значений в несколько переменных, например: read (f, v1,v2,v3,v4).
В Турбо?Паскале также действуют соглашения о разбиении текстового файла на строки. Признаком конца текстовой строки является пара символов с кодами 13 и 10. Можно также использовать модификацию функции чтения с именем readln. При этом после окончания чтения функцией readln
указатель файла автоматически устанавливается на начало следующей строки. Сами символы конца строки игнорируются.
Функция записи write (f, v1,v2,v3,v4) помещает в текстовой файл один символ из переменной типа char, символьную строку из переменной типа string и символьную запись числа из числовой переменной. Если же для записи используется функция writeln, то после последнего выведенного значения вставляется конец строки.
Функции write и writeln используют средства форматирования для управления видом выводимых чисел. Например, write (f, n:10:3) означает, что число n записывается текстом ширины 10 с тремя цифрами после десятичной точки, причем запись выравнивается вправо.
Если в функциях read, readln, write и writeln
отсутствует файловая переменная, то в функциях чтения подразумевается стандартный текстовой входной файл input (обычно клавиатура), а в функциях записи подразумевается стандартный текстовой выходной файл output
(обычно дисплей).
Вывод на дисплей в текстовом и графическом режиме
Стандартный экран монитора состоит из отдельных точек - пикселов. Каждый пиксел может быть окрашен в определенный цвет. Обычно это один из 24=16 цветов. В более совершенных компьютерах пиксел можно окрасить в 28=256 цветов. Если используется 16 цветов, то для описания цвета пиксела требуется 4 байта. При стандартном размере экрана 640*480 пикселов для полного описания экрана требуется 153.6Кб.
Монитор может работать в двух режимах - текстовом и графическом. В графическом режиме можно управлять окраской каждого пиксела в отдельности. В текстовом режиме экран разбивается на строки и столбцы (обычно 25 строк и 80 столбцов), и в каждой клетке изображается символ (один из 256). Изображения символов хранятся в специальной таблице, называемой знакогенератором, и представляют собой совокупность выделенных клеток в прямоугольной матрице.
Состояние экрана задается строкой из 80*25*2=4000 байтов - по два байта на каждый символ. Первый байт - это код символа, первые четыре бита второго байта - это цвет символа (всего возможно 24=16 цветов), другие четыре бита второго байта - это цвет фона, на котором нарисован символ (всего возможно 23=8 цветов, еще один бит задает мерцание символа). Содержимое строки хранится в специальном разделе оперативной памяти, называемом видеопамятью. Физически видеопамять входит в состав монитора, а логически ей зерезервировано место в оперативной памяти (с адресами от A000 до DFFF в 16-ричной системе счисления). Содержимое видеопамяти можно менять программным образом. Параллельно электронная трубка с определенной тактовой частотой выводит содержимое видеопамяти на экран монитора, формируя изображение.
Для изменения содержимого видеопамяти в текстовом режиме в Турбо-Паскале предусмотрен ряд процедур и функций. Перечислим основные из них (кроме функции write, описанной ранее).
Процедура window(l,u,r,d) устанавливает активное окно экрана, занимающее область от u-ой до d-ой строки и от l-ого до r-ого столбца включительно. После вызова процедуры window во всех процедурах вывода на экран текстовой информации номер строки и номер столбца отсчитывается от верхнего левого угла окна и действителен только в пределах окна.
Процедура textcolor(k) устанавливает текущий цвет символа, где k - число от 0 до 15, нумерующее один из цветов символа (если k>15, то берется остаток от деления на 16).
Процедура textbackground(k) устанавливает текущий цвет фона (k от 0 до 7).
Процедура clrscr очищает окно с установленным цветом фона.
Процедура gotoxy(j,k) устанавливает курсор в к-ой строке и j-ом столбце (строки нумеруются от 1 до 25, столбцы - от 1 до 80).
Функции wherey и wherex (без параметров) возвращают номер строки и столбца текущего положения курсора.
В графическом режиме координаты пиксела на экране задаются номером столбца (от 0 до максимального значения) и номером строки (от 0 до максимального значения). Каждый пиксел может иметь один из 24=16 цветов и задается половиной байта. Итого для изображения цветного экрана при размере экрана 640*480 необходимо 153.6Кб. В принципе программным путем можно управлять светимостью каждого пиксела в отдельности, однако обычно на экране закрашиваются целые области. Как и в случае текстового режима, в Турбо-Паскале для управления изображением предусмотрен ряд процедур и функций.
Связка из вызовов двух процедур
detectgraph(graphdriver,graphmode);
initgraph (graphdriver,graphmode,’ ’);
автоматически определяет на диске файл программы работы с графическим экраном (файл драйвера экрана) и переводит монитор в графический режим работы с экраном, использующий этот драйвер. В зависимости от драйвера экран может иметь разное число строк и столбцов. Процедура сloseпraph прекращает работу с экраном в текстовом режиме и возвращает монитор в текстовой режим.
Функции getmaxy и getmaxx
возвращают максимальное число строк и столбцов экрана, используемых в текущем графическом режиме.
Процедура setviewport(l,u,r,d,w) устанавливает активное графическое окно экрана, занимающее область от u-ой до d-ой строки и от l-ого до r-ого столбца включительно. После вызова процедуры setviewport во всех процедурах вывода на экран графической информации номер строки и номер столбца пиксела отсчитываются от верхнего левого угла окна и действительны только в пределах окна.
Параметр w определяет характер вывода изображений в окне: если w=true, то изображение усекается, а если w=false, то изображение продолжается за границы окна.
Процедура setcolor(k) устанавливает в качестве текущего цвет с номером k (число от 0 до 15). Этот цвет используется в дальнейшем для рисования всех линий (прямых, дуг, многоугольников, окружностей).
Процедура setbkcolor(k) устанавливает в качестве цвета фона цвет с номером k (число от 0 до 15). В результате действия процедуры изменяется цвет всех тех областей окна, которые служат фоном изображения.
Процедура setlinestyle(<вид линии>,<образец линии>,<толщина>) устанавливает стиль проведения линий, прямоугольников и многоугольников. Целые константы <вид линии> и <образец линии> задают сплошную, точечную или пунктирную и т.п. линии, <толщина> в пикселах равна 1 или 3. Установленный стиль используется при проведении линий до тех пор, пока он снова не изменится.
Процедура setfillstyle (<штриховка>,k) устанавливает вид и цвет узора, которым будут заполняться области на экране. Узор представляет собой рисунок цвета k
на фоне, установленном процедурой setbkcolor. Значение штриховки, равное 0, соответствует отсутствию узора вообще, значение 1 обозначает сплошное закрашивание цветом узора.
Процедура cleardevice устанавливает положение окна и всех параметров рисования и заполнения в исходное состояние (например, окно во весь экран и черный цвет для фона).
Процедура clearviewport очищает окно черным цветом.
Процедура moveto(x,y) устанавливает курсор в y-ой строке и x-ом столбце. Процедура moverel(dx,dy) сдвигает положение курсора на dx столбцов вправо и dy строк вниз.
Функции gety и getx (без параметров) возвращают номер строки и столбца текущего положения курсора.
Процедура putpixel(x,y,k)
окрашивает пиксел в y-ой строке и x-ом столбце в цвет с номером k.
Функция getpixel(x,y)
возвращает цвет пиксела в y-ой строке и x-ом столбце.
Процедура line(lx,ly,rx,ry)
вычерчивает линию от точки с координатами (ly,lx) до точки (ry,rx)
текущим цветом и текущим стилем. Процедура lineto(x,y) вычерчивает линию от текущего положения курсора до точки (y,x). Процедура linerel(dx,dy)
вычерчивает линию от текущего положения курсора до точки, сдвинутой на dy
строк и dx столбцов вправо.
Процедура rectangle(lx,ly,rx,ry)
вычерчивает текущим цветом и текущим стилем прямоугольник, левый верхний угол которого имеет координаты (ly,lx), а правый нижний угол - координаты (ry,rx).
Процедура circle(x,y,r)
вычерчивает текущим цветом и сплошной линией текущей толщины окружность с центром в точке с координатами (y,x) и радиусом r.
Процедура arc(x,y,a,b,r)
вычерчивает дугу окружности с центром в точке (y,x) и радиуса r
от начального угла a до конечного угла b. Углы отсчитываются в градусах против часовой стрелки.
Процедура floodfill (x,y,k)
закрашивает заданным узором замкнутую область, ограниченную контуром цвета k, внутри которого лежит точка с координатами (y,x). Если такого контура нет, то будет закрашено все окно.
WWW (World Wide Web - всемирная паутина)
WWW– сейчас самый популярный сервис Интернет. Весьма непросто дать корректное определение WWW. Вот некоторые из эпитетов, которыми она может быть обозначена: гипертекстовая, гипермедийная, распределенная, интегрирующая, глобальная. Ниже будет показано, что понимается под каждым из этих свойств в контексте WWW.
WWW работает по принципу клиент-сервер: существует множество серверов, которые по запросу клиента возвращают ему документ, состоящий из частей с разнообразным представлением информации (текст, звук, графика, трехмерные объекты и т. д.), в котором каждый элемент может являться ссылкой на другой документ или его часть. Формат документов, использующихся в WWW для предоставления информации, называется языком HTML (HyperText Markup Language - язык разметки гипертекста). Ссылки в документах WWW организованы таким образом, что каждый информационный ресурс в глобальной сети Интернет однозначно адресуется, и документ, который Вы читаете в данный момент, способен ссылаться как на другие документы на этом же сервере, так и на документы (и вообще на ресурсы Интернет) на других компьютерах Интернет. Причем пользователь не замечает этого, и работает со всем информационным пространством Интернет как с единым целым. Программы-клиенты WWW, называемые броузерами или навигаторами, понимают такие ссылки. Программные средства WWW являются универсальными для различных сервисов Интернет, а сама WWW играет интегрирующую роль.
Формат HTML описывает структуру и связи документа. Внешний вид документа на экране пользователя определяется конкретным броузером. Имена файлов в формате HTML обычно оканчиваются на html (или имеют расширение htm в случае, если сервер работает под MS-DOS или Windows). Протокол, по которому взаимодействуют клиент и сервер WWW, называется HTTP (HyperText Transfer Protocol - протокол передачи гипертекста). Ссылки на информационные ресурсы Интернет называются URL-адресом (Uniform Resource Locator - универсальный указатель на ресурс).
В языке HTML поддерживаются формы. Пользователь вводит в них некоторую информацию, которая затем может передаваться на сервер. Таким образом заполняются анкеты, регистрационные карты, проводятся социологические опросы.
Изменения в стандартах HTML затруднены децентрализованностью WWW, так как стандартом становятся не те расширения языка HTML, которые лучше, но те, которые привносятся самыми популярными навигаторами, такими как Netscape Navigator. Децентрализованность несет и множество других проблем: отсутствие общего каталога серверов и средств тотального поиска по ним. Однако и эта проблема решается, причем более успешно, чем предыдущие - сегодня есть и каталоги, и поисковые системы, которые, если и не являются глобальными, то тем не менее охватывают достаточно большую часть документов WWW, чтобы быть полезными и успешно применяться для поиска информации.
